Third party platforms are a risky foundation for your content moat
AI crawlers and foundation models are quickly becoming the primary way information is discovered, summarised, and acted upon, often before anyone even sees a traditional search result.
For brands and publishers, the real question is no longer just, “Can people find my site in Google?” It is now: “Do AI systems have permission to access, interpret, and use my content in the first place?” When you map which major third-party platforms allow or block specific AI bots, you start to see who is quietly influencing training data and who is slowly fading from the AI-mediated web.
At the same time, many creators and businesses have built their content and audience relationships on “rented land”. Social networks, creator platforms (like Medium and Substack), and SaaS tools sit between you and your audience. If those platforms decide to block, throttle, or aggressively license their data to AI vendors, your visibility, entity signals, and reach can shift overnight. This research turns a vague platform risk into something measurable.
For CMOs, this is not a technical nuance. It is a revenue question. If AI systems cannot access, interpret, or trust your core content, your brand risks disappearing at the very moment prospects are researching solutions – long before they reach your site, your sales team, or your paid channels.
You can clearly see which hosts support or restrict your presence in AI systems, how that affects entity building and audience ownership, and then make intentional infrastructure decisions rather than leaving them to platform policy changes.
So we did a little experiment
To explore this, we reviewed 34 platforms where you can host content outside your own domain. We cross-referenced them against 28 commonly identified AI user agents, alongside CommonCrawl (CCbot).
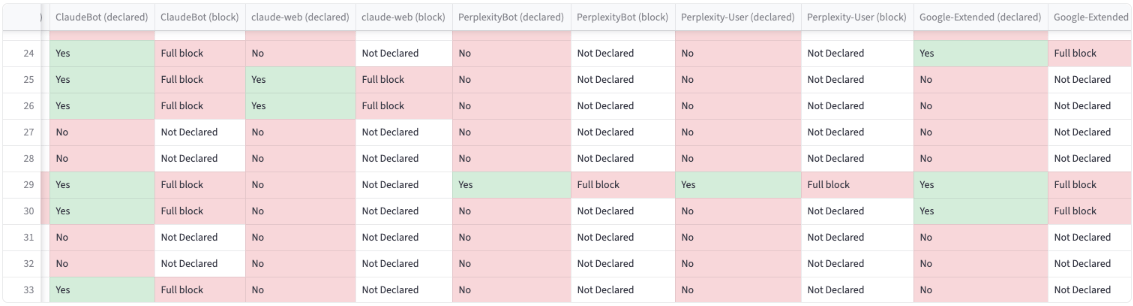
And here’s what we found
- 13 websites block at least one AI crawler.
- 7 block CCbot, and all 7 of these also block AI crawlers, creating a 100% overlap.
- 21 sites do not block any AI crawlers.
Grouped by content site type:
| Category | Sites in group | Avg AI bots blocked | Min | Max |
|---|---|---|---|---|
| Publishing | 23 | 1.13 | 0 | 7 |
| Social | 7 | 11.71 | 0 | 18 |
| Tooling | 4 | 0.25 | 0 | 1 |
Across the third-party content platforms analysed, the most frequently blocked AI crawler was ClaudeBot (29.4%), followed by GPTBot (23.5%), Google‑Extended (20.6%), Bytespider (20.6%), and CCBot (20.6%).
RAG vs fine-tuning, and why blocking certain bots matters
Retrieval-augmented generation, or RAG, allows a language model to fetch information at query time. Training data, by contrast, is what the model originally learned from during pre-training or fine-tuning.
With RAG, the model connects to an external knowledge source such as documents, databases, or a search index and pulls relevant snippets into the prompt before generating an answer. The model’s internal parameters remain unchanged. To keep answers current, you update the external knowledge base instead of retraining the model.
Training data works differently. It modifies the model’s internal weights, embedding language patterns, facts, and behaviours directly into the system. Updating what the model “knows” in this way requires another training or fine-tuning cycle, which is slower and becomes outdated as the world changes. This approach works well for stable behaviours, domain terminology, or stylistic patterns, but it struggles with fast-changing information.
In practical terms, RAG means bringing documents to the model at run time, giving you a flexible and inspectable knowledge layer outside the system itself. Training data means embedding knowledge directly into the model, creating stronger internal fluency, but leaving that knowledge static and opaque once training ends.
Most modern systems use both: a robust base model trained on broad datasets, combined with RAG to inject fresh, organisation-specific, or time-sensitive information during responses.
This distinction has real implications. You can block AI crawlers used for RAG and still allow CCbot, meaning your content may appear in large language models through training data. The reverse is also true. Models may also learn about your brand through third-party platforms that you do not control, even if you restrict direct AI access to your own domain.
AI training and data control risks
In most cases, you have limited control over how content on platforms is used for AI training. Prompts, posts, and engagement data may be absorbed into models and are effectively impossible to remove later. If a platform updates its AI policies or changes how it handles robots.txt, your content could suddenly become more or less accessible to crawlers and models without any direct input from you.
Entity building and knowledge graph signals
Entity SEO depends on consistent, controllable signals such as structured data, organisation markup, and sameAs links across multiple sources to clearly define and reinforce your brand as a distinct entity.
When your primary content lives on third-party domains, their entity is strengthened more than yours. Platforms like Medium, LinkedIn, or Substack accumulate the co-occurrence signals, links, and contextual associations, while your own domain plays a smaller role in the knowledge graph.
If a platform changes URL structures, restricts features, adds paywalls, or shuts down entirely, you lose entity signals that you cannot easily migrate. Backlinks, internal linking paths, and historical context often remain trapped within that ecosystem.
Audience ownership and distribution fragility
You do not truly own follower lists or engagement graphs in a portable format. Moving an audience off-platform later can be expensive and limited by conversion rates.
Each transition requires convincing people to take another step, whether that is subscribing, signing up, or following elsewhere.
Organic reach continues to decline as platforms prioritise monetisation and their own AI features. You may find yourself paying an ongoing attention tax to reach an audience you originally built, competing within feeds that increasingly favour platform interests over creator visibility.
A more resilient model: hub-and-spoke
A more resilient long-term strategy is the hub-and-spoke model. Use third-party platforms as discovery channels that direct people towards assets you control, such as your primary domain, email list, or community space, rather than treating them as the permanent home of your core content.
Keep canonical, structured, and evergreen material on your own domain. This gives AI agents and search engines a stable, brand-owned reference point to connect mentions, entity signals, and training data back to you.
Where possible, design or negotiate data practices that limit how deeply vendor AI systems can retain or reuse your audience and behavioural data over time.
The goal is not to abandon large platforms. Exposure on Medium, LinkedIn, and Substack can increase growth and discovery. The key is balance, leveraging their reach without surrendering control of your content, your entity footprint, and your long-term audience relationship.
SALT.agency can audit your AI crawler exposure, entity signals, and platform dependencies – and show you where you are exposed, where competitors are ahead, and what to fix first. Get in touch.


