Verify which pages/URLs on your site have been indexed using Screaming Frog
How do you check which pages/URLs on your site have been indexed on Google?
I am acutely aware that this subject has been covered so many times in the past, using various methods, from Paul Shapiro’s Phyton’s script, which apparently upset the powers that be, understandably, as bulk checking Google index is against G’s terms of services, so I must caveat here that scraping Google index is against Google ToS.
Then there are a whole host of other tools/software you can use like URL Profiler or Scrapebox to perform this task.
However, when I googled to see if any of the methods involved utilises Screaming Frog, which is arguably one of my favourite SEO softwares out there, I couldn’t quite find the results I was hoping for.
I did some more digging to see if this was actually a possibility or a thing and discovered that you could actually do it, well kind of, but you need a proxy, and the right configuration on Screaming Frog or you’ll get blocked.
Like any other things in SEO, you need to experiment, test and do some more test, tweak and fine tune your test to get better results, so I decided to experiment with this.
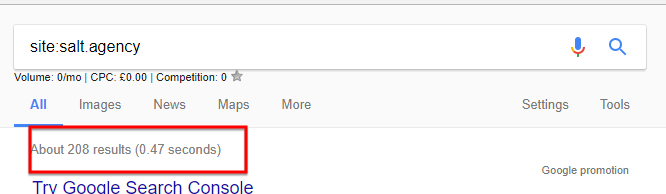
First, make sure you check the number of pages on your site that are currently indexed in Google by performing site:yoursitedomain.com as well as cross check that result with your site’s Google Search Console property index status – to do that go to your GSC then go to Google Index > Index Status.
For this experiment, I’ve used our website: https://salt.agency/ and these were what I got:
Site: search
GSC
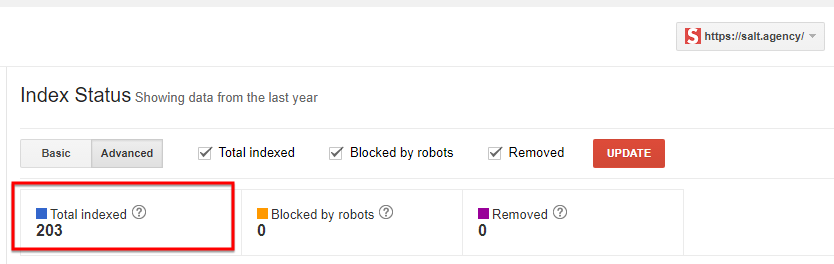
I’d caveat that don’t take the site: search as a gospel as the result is quite often skewed or not always accurate but it does give you a good representation on how many pages are currently indexed and also if there’s a great disparity between the site search and your index status, then there’s an underlying site’s index issue you need to investigate.
In our case, the results I got matched quite nicely. Okay, there’s a slight difference but it’s very negligible so it’s reassuring to know our site doesn’t have indexing issues, as we would expect!
What you need next is the list of all URLs in your XML sitemap. Download the list by using the ‘download sitemap’ option on Screaming Frog or ‘download sitemap index’ if you have specialty XML sitemaps.
Once finished, export the result and get all the URLs and copy and paste them into a new excel sheet.
What you need next is take Google’s cache command – https://webcache.googleusercontent.com/search?q=cache: and append the URLs from your sitemap to it using the concatenate function on Excel.
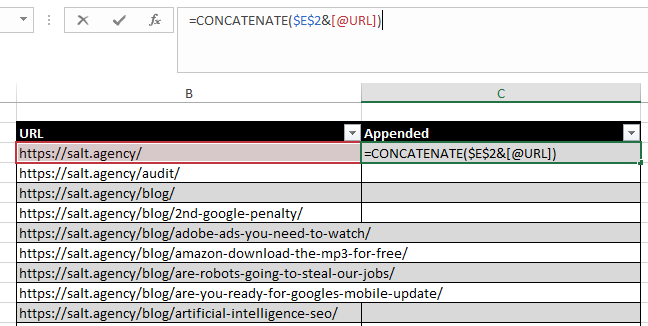
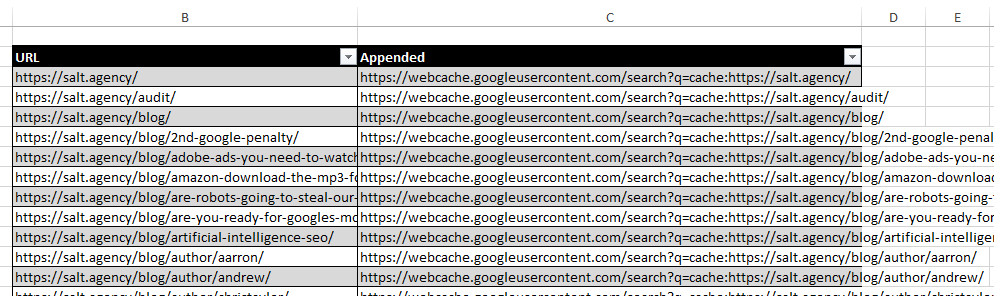
Once you’ve got the list of appended URLs, you upload them in list mode on Screaming Frog. Remember, you need a proxy to this or your IP will get blocked for essentially scraping Google results. Some configurations to bear in mind before you hit the OK button.
Use Proxy
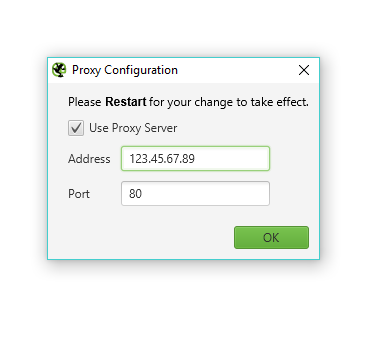
Don’t forget to restart Screaming Frog when using a proxy for the change to take effect.
Pro tip: for maximum protection of your IP address from being blocked, use a VPN on your machine to obfuscate your machine’s IP address or use something like Hidemyass, a program that auto changes your machine’s IP every 15-30 seconds etc – it auto switches, which is pretty dope.
Adjust the Screaming Frog crawl speed
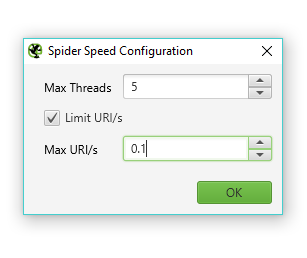
For more information on adjusting speed and using proxy on Screaming Frog, check this useful page!
Once you’ve got everything set and the froggy is ready to crawl, upload the URLs manually then hit OK.
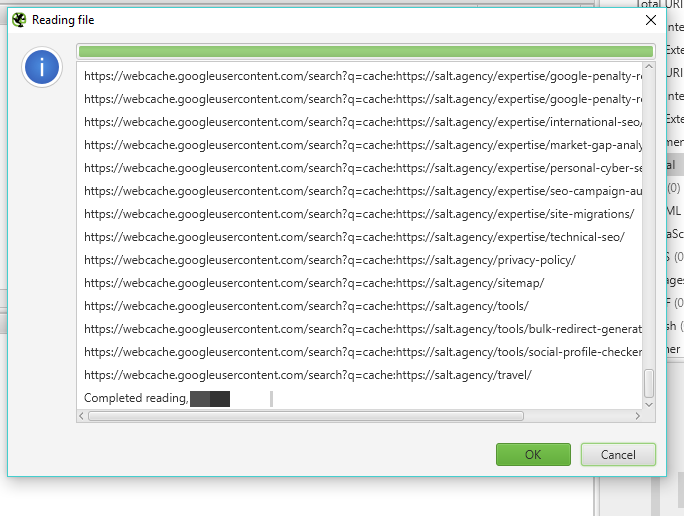
When I conducted this the first time, I got the configuration wrong, hence, the results were returning this:

When you look at the detail in froggy, you’ll see this:
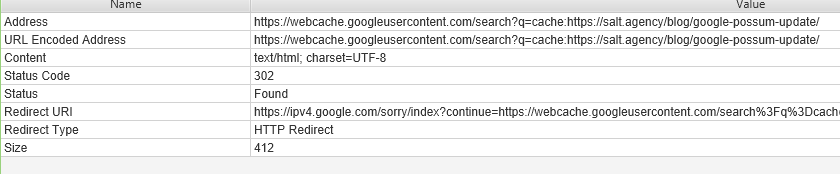
Yeah, I got kicked. But then I tweaked the crawl speed and enabled a VPN in my machine and then I was seeing this:
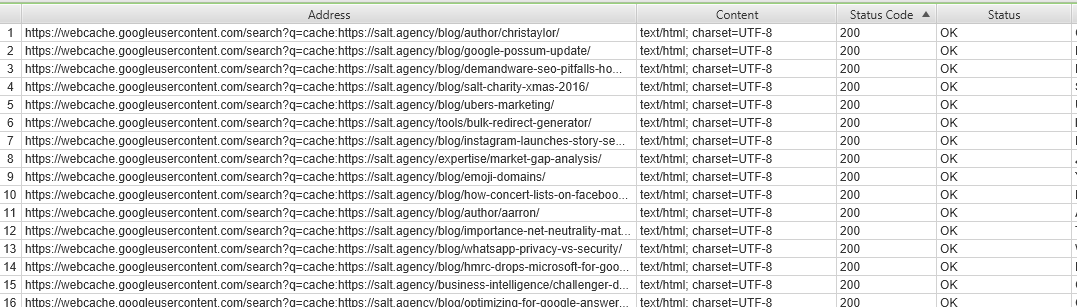
Pretty sweet.
What you can take from this is when a page is indexed (hence, cached) then it returns a 200 response code, when it returns a 404 header then it’s not indexed, hence it’s not cached. For example, I saw this:
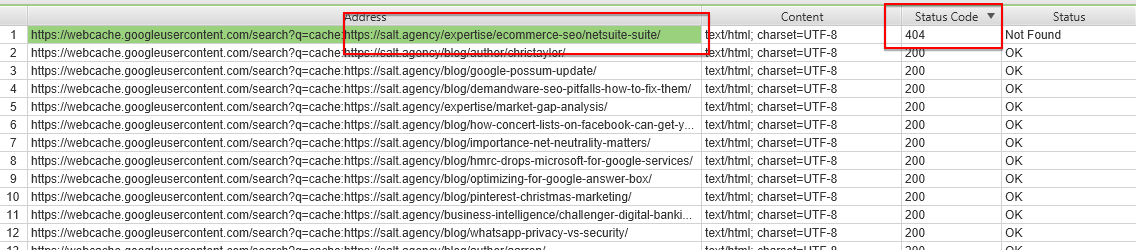
That’s basically saying that there is no cache for this URL: https://salt.agency/blog/local-search-success-in-2016/
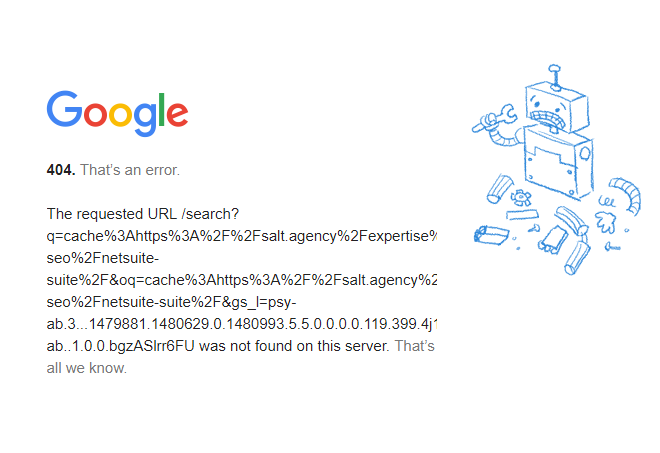
And if you perform info:URL
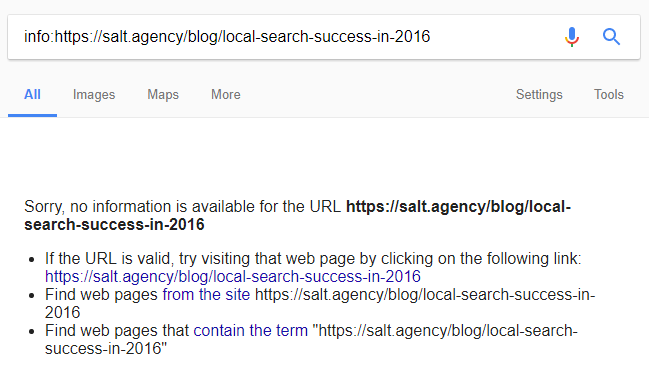
However, performing site:URL I got this:
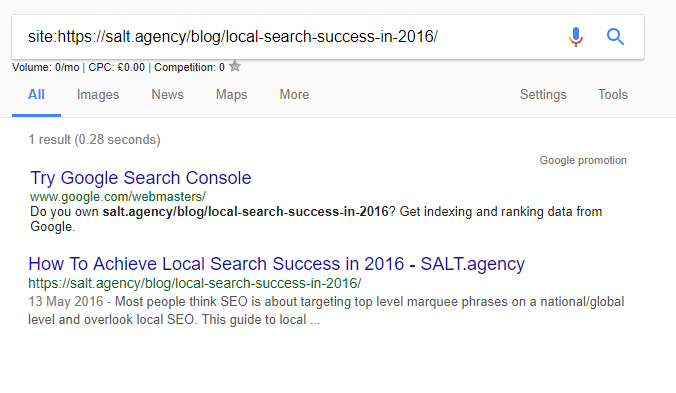
What do these mean? What has this experiment taught me?
I could definitely caveat this experiment until the cows come home but here are some of my key takeaways:
- Checking real indexing is tough. Even if you could, you could never be 100% sure of the results, just because, Google!
- Checking to see if a page is cached is not 100% full proof that a page is indexed, but neither performing site:query or info:query.
- On another day, I could guarantee that I would have got very different results or that I would get sod all for a site:query.
- I am of the belief that none of the commands are reliable to check for page indexing, just because, Google! A URL can sometimes appear for an info:query, but if you search for it by literally searching for the URL, no results are returned and they never get any traffic.
- Therefore, if you ever see indexable URLs they just mean HTML with 200 status codes, without a noindex, or canonicalised, etc.
- My favourite method is still checking and analysing your server log files to see if Google bots, or any other search engine user agents for that matter, ever crawled a URL. But that in itself isn’t a guarantee that the Google will index that URL.
- I contacted Dan Sharp from Screaming Frog and he has confirmed that a proxy list feature on Screaming Frog, like that of Scrapebox’s or URLProfiler’s, is definitely on their to-do list so that could be something useful to perform this experiment as then the froggy could switch the proxy every 10-20 seconds automatically.
The challenge is to find a way to make it scalable but that’s a question for another day I should think.
Finding a way to make this work consistently is still a challenge, unless you have some ideas you’d like to throw in to make this better? Let me know your thoughts!
Update: Gerry White just pointed out that to make the crawl results infinitely better, you could also connect the froggy to GA and GSC and get the sessions, clicks, impressions data and what have you. So you’ve got the cached data to verify the indexed page on the one column and on the other columns you can correlate the results with the page’s GA and GSC data.


