SEO Questions: How Do Search Engines Crawl The Internet?
Search engines use automated crawlers — also known as robots or spiders — to travel from page to page and from link to link, to collect pages that they deem high quality.
Search engines frequently crawl websites, typically daily, to determine which pages should be indexed in their massive databases.
Over time, search engines continue to request previously downloaded pages to check for content updates. A certain amount of bandwidth is then allocated for these reviews based on the pages’ calculated relevancy.
Every time a page is downloaded, bandwidth is used, and once a website’s allocated bandwidth limit is reached, no more pages will be crawled until the next review.
This is referred to as a site’s crawl budget, and it works just like any other budget. But in the case of a search engine, when your site’s crawl budget has been exhausted, the bot moves on.
You can see how your website is being crawled by looking in Google Search Console (their webmaster tools) in the ‘crawl stats’ report:
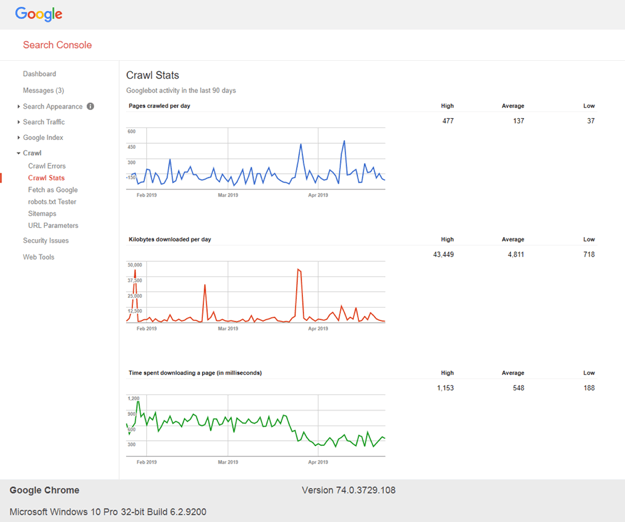
Since there is a limited amount of allotted bandwidth, it is crucial to direct crawlers to the content you want to be included in the search engine’s index of web content. This usually means removing or blocking any duplicated or low-value web pages.
To use your site’s crawl budget effectively, it’s important to investigate errors reported in Google Search Console to make sure that those pages render properly.
If a page can’t be fixed, due diligence must be applied to make sure the page doesn’t negatively impact the rest of the site. This can be done in several ways:
- 301-redirect these pages to their new URLs. Use a 302 if the redirect is truly temporary (e.g., a product that’s out of stock).
- If you have a lot of missing pages, allow them to return a 4xx (e.g., 404, 410) status code but remove these pages from your XML sitemap(s).
- Remove any internal links pointing to these error pages.
- If any of your 4XX pages have received significant traffic or links, you need to make sure you 301 redirect these pages.
Search engines and bots
All search engines crawl the internet in a similar way explained above, but search engines differ in how they index and rank this content.
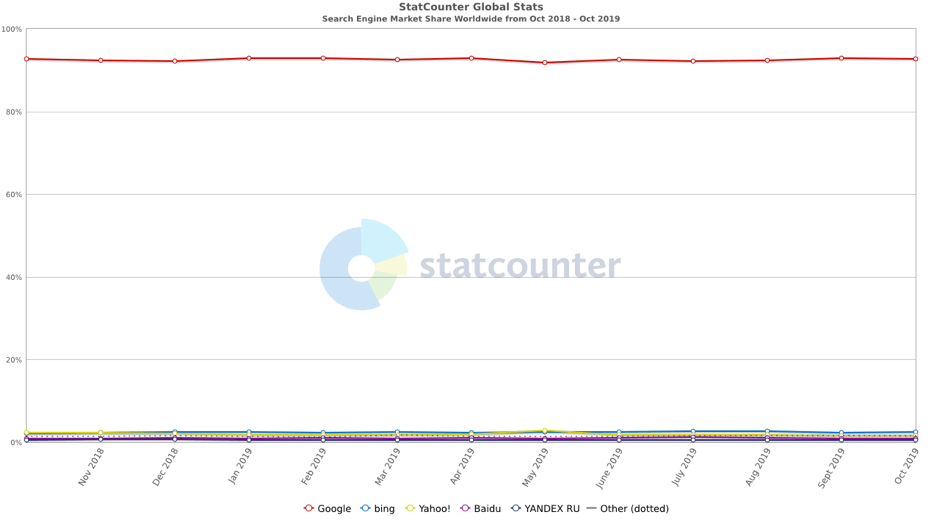
One search engine, in particular, is ahead of the rest in this, having a huge worldwide market share (excluding China) of about 90%, which is – of course – Google.
Search engines all have their own bot and specific user-agent which they crawl with, letting websites know who is crawling their website. This allows sites to block specific crawlers if necessary.
Google has different types of bots that have different jobs when crawling the web, this helps them segment the data they retrieve from their crawling and make storing and organising it easier.

The most common ones we come across in technical SEO are Googlebot Desktop and Mobile, but this does not mean the other ones are not important, especially depending on the type of website.
Since Google switched to mobile-first indexing in 2018, this has made some webmaster ensure if their website is mobile-friendly for users and Googlebot Mobile.
You can see which bot has crawled your URLs by using the URL inspection tool in the new Google Search Console.
The video below from Google’s Matt Cutts briefly explains how crawling works, and then gives a simplified explanation of indexing. The piece gives a general overview of the topics we will be going into more technical detail in this guide:
https://www.youtube.com/watchv?=BNHR6IQJGZsXML Sitemaps
XML sitemaps are designed to help search engines discover and index your site’s most valuable pages. Think of these pages as a site’s crème de la crème content.
The sitemap consists of an XML file that lists all the URLs of the site that you want to compete in organic search, which is, simply put, all pages you want search engines to see.
This XML file also contains ancillary information, such as when a page has been updated, its update frequency, and relative importance.
Google recommends creating separate sitemaps for different types of content; images, videos, and text, for example.
It is also important to update them each time new content is published with a multi-format XML sitemap, image, or video XML sitemap. This is typically automated using the CMS the website runs on.
It is important to update the sitemap only with the original, canonical versions of the URLs. They should not redirect or return errors. In other words, every page in the sitemap should return a ‘200’ status code.
Anything other than a ‘200’ status code is regarded by the search engines as “dirt” in a sitemap. Duane Forrester of Bing said that the Microsoft search engine only tolerates a 1% of dirt in a sitemap. When asked what qualified as dirt, he replied, “Anything that doesn’t return a 200 status code.”
Finally, you should upload these sitemaps to Google and Bing’s Webmaster Tools. Google will tell you how many of the submitted URLs have been submitted and how many of those have been indexed, whereas Bing just tells you how many URLs were submitted.
HTML linking
The way in which search engines crawl has been the same; they crawl through the HTML code of a website and branch out to the links within these pages, thus enabling them to crawl the internet.
For websites to be crawlable, they must have links to each of their webpages within the HTML. This is widely done today, with many websites linking to their content in a main navigation header, and within the body of these pages.
This means that links should not be served in technologies such as JavaScript or, even worse, Flash.
HTML sitemaps
An HTML sitemap lists the URLs for a website, like an XML sitemap, but is simply delivered in an HTML file instead. HTML sitemaps tend to contain fewer URLs than an XML sitemap, only containing the important URLs, or landing pages, of a website.
HTML sitemaps are usually linked to in the footer of a website and are very useful to Bingbot (Bing’s crawler), and make a nice addition on UX.
GSC Error Reporting
Google Search Console has a lot of in-depth features which all are highly useful to webmasters to ensure that their website is okay for Google to crawl.
Monitoring these is a good way of keeping your site in check, for if Google flags something, it’s probably a wise choice to check and fix it.
Crawlable JS
Google is the filing system, equipped with a Chrome 41 engine, and this is a good introduction as to how it works by Google themselves:
For the most part, the only major search engine which can execute (simple) JavaScript is Google.
It crawls JavaScript as it runs across it within the HTML. As Google crawls webpages, it will execute JavaScript as soon as it sees it, much like the browser.
It is important to ensure that the JavaScript does not break the webpage and is not too complex or demanding for Google to crawl.
JavaScript can be inserted as an external script or be placed inline with the HTML document. This, however, is not suggested as Google struggles more with inline JS, especially when it grows.
Server Uptime
This is not an issue to most websites, however, is still something to be conscious of.
To Google, a website must always be readily available 24/7 for itself and users. Google crawls websites a lot, every day, and thus expects to be able to crawl content when it wants to.
When you suffer from downtime or are under maintenance, you’re taking away Google’s ability to crawl website content, which can affect SEO (depending on how long the downtime lasts).
Websites must have a good webhost to ensure that this does not happen.


