Classifying 200,000 articles in 7 hours using NLP
Every now and then, consultancy firms face challenges that are abnormal and create new solutions. We faced that last year, to classify over a quarter of a million articles with a very limited budget. Our target was that if we can classify over 80% of them automatically with a 90% accuracy, then we can do the rest manually within budget; and that’s what we exactly did, through the use of Artificial Intelligence.
Why AI? Because without it, we simply could not process the amount of data that was being generated within the time constraints we have. AI is not a new thing, nor is Natural Language processing.
What is Natural Language Processing (NLP)?
Natural language processing (NLP) is the branch of AI concerned with linguistics. It focuses on teaching machines how to understand and communicate using human language. Because language is so important to our lives, NLP will most certainly create tons of value to humanity. In fact, if we look under the hood of some of today’s most valuable tech companies, we would find NLP powering many key products such as online search engines, translation, voice-assistants, chatbots, and many more in different industries.
Why did NLP take off in the past year and a half?
Today, 10% of Google’s searches are powered by BERT, a deep learning NLP model. This was all thanks to deep learning, GPUs, and a technique called transfer learning. The idea of transfer learning is to teach a model how to perform a task so that when we train it for a new and related task, it has better performance.
Transfer learning was originally very successful in the field of computer vision. Back in 2014, when researchers started pre-training models on the ImageNet dataset, and then “transferring that knowledge” to a variety of other tasks like object detection.
It was not until 2018 that the “ImageNet moment” happened in NLP when researchers started pre-training text models on massive amounts of news and Wikipedia articles using the language modelling task. An early example of this approach is ULMFiT from May 2018, with just 100 labelled examples, it could match the performance of training a model from scratch (no pre-training) with 100x more data.
Where is it today?
As the year went by, we started pre-training NLP models on more and more data. That brings us to today, with the latest models BERT and XLNet taking over the field. Pre-training these models is led by the large tech companies, and then at some point, they release the model to the public. Google and other large companies spend up to $60k just in computers to pre-train an XLNet model.
How NLP works
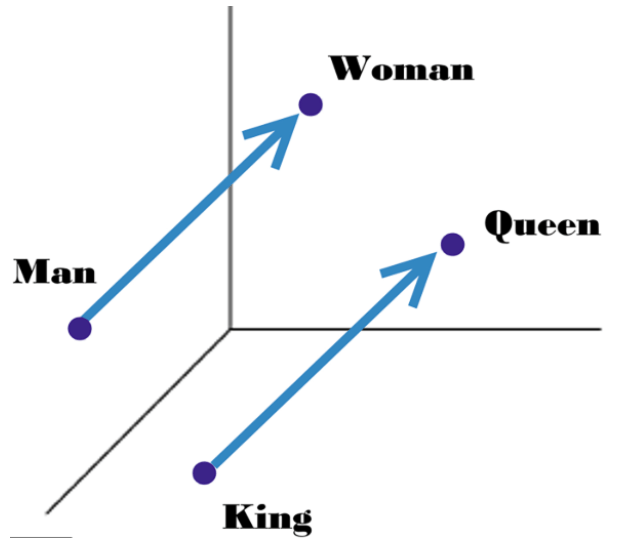
Obviously, it’s a complex field that takes years to master. But, to put it simply, NLP works by detecting different patterns in text and trying to use those patterns towards some useful application. For example, “word embeddings” are numerical vectors associated with each word in our vocabulary, calculated on which words appear near on another. In other words, it applies the old saying “show me who your friends are, and I’ll tell you who you are” to words. Using these vectors, a computer can start solving analogies such as “man is to woman as king is to ____? Queen!“.
Core tasks in the NLP field
There are many core tasks that NLP academic focus on solving, and as they make progress, the technology moves into the industry and unlocks new people-facing products.
Here’s a list of some of the most important NLP tasks:
- Text classification: the task of assigning a document or sentence to a particular category.
- Sentiment analysis (positive vs negative)
- News classification
- Intent detection
- Spam detection
- Named entity recognition: tagging all the entities in text with their corresponding type.
- Companies
- People
- Locations
- Relation extraction: finding semantic relationships between entities in text.
- [Person X] Married to [Person Y]
- [Person X] Works for [Company Y]
- Syntax analysis: analyse the syntactic structure of sentences.
- Speech recognition: translating voice data into text.
- Summarisation: producing a short version of a given text, while keeping most of its meaning.
- Question answering: being able to find the answer to a question within a given text.
- Coreference resolution: determining what entity words like “he” or “she” refer to.
Text classification
Text classification is the task of assigning a document or sentence to a particular category according to its content.
There are two types of text classifiers:
- Binary: when the model’s job is to classify a piece of text into one of two categories. For example, when a human reads an email and decides if it’s urgent or not, they are classifying it between “urgent” or “not urgent”.
- Multiclass: when the model’s job is to classify a piece of text into one of three or more categories. For example, when a human reads a news article and decides what topic it’s talking about out of many (Sports, Politics, Business, or Technology).
To teach a machine how to classify text automatically, be it binary or multiclass, we start by labelling examples manually and feeding them to a text classifier model. The model will then find patterns in the data and estimate how informative each pattern is to predict the given labels. Then, you can feed completely new examples to the model to predict the category automatically.
Why is NLP so useful?
Text is everywhere: news, websites, social media, PDFs, emails, and more. IBM estimates that 80% of the world’s data is unstructured, and businesses only have visibility into a small portion of this information. That’s mainly because reading text and extracting insights is very time-consuming for humans. However, text classification can read and categorise a document or understand which are the key insights within a document. This is why organisations that want to augment decision making and optimise processes turn to text classification.
For example, a text classifier can read a document and highlight key insights with different colours according to its type:

So, how do we use text classification to categorise our dataset of news?
Our end goal is to classify a million news documents into one of 4 categories automatically. To do this, we need to build a multiclass classification model, and then use it to predict the label of our million documents.
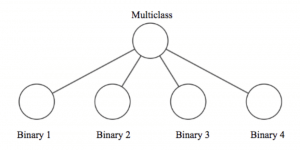
Our machine learning approach to multiclass classification
To build our multiclass classifier, we train four individual binary classifiers independently, one for each category. When given an example to classify, we get a label and confidence-score from each classifier and then integrate them into a final answer.
We’ve seen this modular design pattern being used across the tech industry and after taking all the pros and cons into account, we believe in most cases it is the best practice for building and maintaining multiclass models.
Below is a visual representation of the architecture:
Main advantages:
- Labelling is simpler and faster because human annotators need to pick only between two options, rather than between many.
- It’s easy to add new classes in the future since we just need to add another binary model.
- We can use the binary models for other applications besides the multiclass task at hand.
- We don’t need to worry about class imbalance as much, as long as we have enough examples for each of our binary models.
- It’s easier to focus on building and evaluating a model, one at a time.
- We can use end-user feedback to train the system continuously. For example, when a user indicates that a prediction from a binary model is wrong, the user is effectively labelling that example as the opposite category.
Main disadvantages:
- Longer compute at prediction time because we need to run multiple binary models.
- Can result in extra labelling since the same record could be labelled multiple times for different binary models.
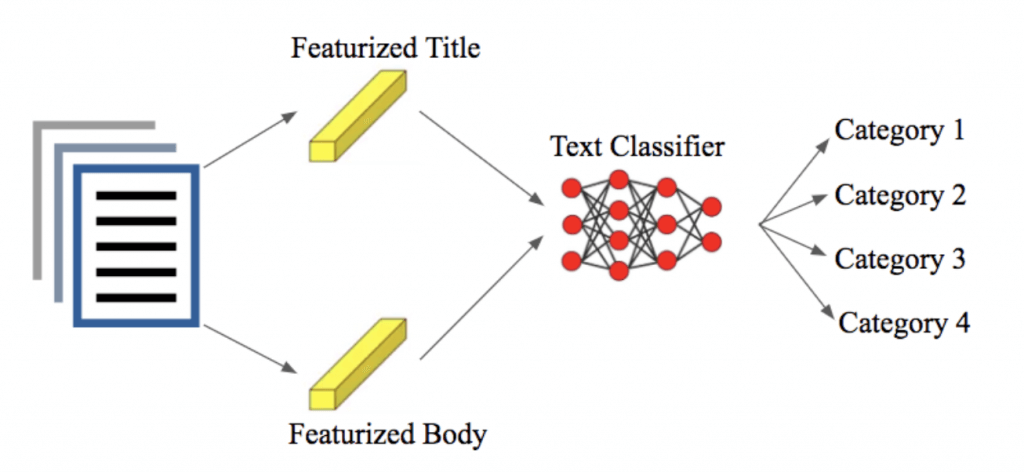
The model’s decision-making process
From our past NLP industry experience, we have learned that news titles tend to have key information that helps AI make correct decisions. Thus, given a news document, the model generates a separate vector representation for the news title and body and then combines them to make a binary prediction. This essentially allows the model to assign different weights to patterns in the title than those in the body and boosts performance substantially.
Sculpt AI Classifier
Sculpt AI, built by Stanford ML experts, in collaboration with SALT.agency’s ML experts., is a code-free AI platform that makes it quick and intuitive to train state-of-the-art classification models through the UI. Once the model is trained, it’s easy to deploy and use the model to make predictions on new data.
Sculpt AI allows you to achieve higher accuracy up to 10x faster. To accomplish this, Sculpt uses a combination of techniques, including weak supervision, uncertainty sampling, and diversity sampling.
- Weak supervision: the human annotator explains their chosen label to the AI model by highlighting the key phrases in the example that helped them make the decision. These highlights are then used to automatically generate nuanced rules, which are combined and used to augment the training dataset and boost the model’s quality.
- Uncertainty sampling: it finds those examples for which the model is most uncertain, and suggests them for human review.
- Diversity sampling: it helps make sure that the dataset covers as diverse a set of data as possible. This ensures the model learns to handle all of the real-world cases.
- Guided learning: it allows you to search through your dataset for key examples. This is particularly useful when the original dataset is very imbalanced (it contains very few examples of the category you care about).
Sculpt AI also makes the process interactive and transparent by showing real-time feedback on how well the model is performing as you annotate. That way, when you reach your desired performance, you can stop labelling examples. You can also visualise the main criteria used by the model to make decisions, which helps make sure that the model behaves as you would expect.
The three steps we took with Sculpt AI:
Labelled examples intelligently
We first uploaded our documents to Sculpt AI, and our SEO experts spent a few hours labelling examples through the UI. As we labelled, we also highlighted key phrases as a way of explaining our decisions to the AI. In the background, Sculpt is training a model in real-time: the first is to cut labelling time by up to 10x (based on tests using standard datasets).
To accomplish this, Sculpt uses a combination of active learning, diversity sampling, weak supervision, and using the highlighted phrases for automatic feature generation. The second objective is to give real-time performance statistics so that we don’t have to label any extra examples.
For example, we could track the precision-recall curve as we labelled and decide to move on to the next step when we were happy with the performance.
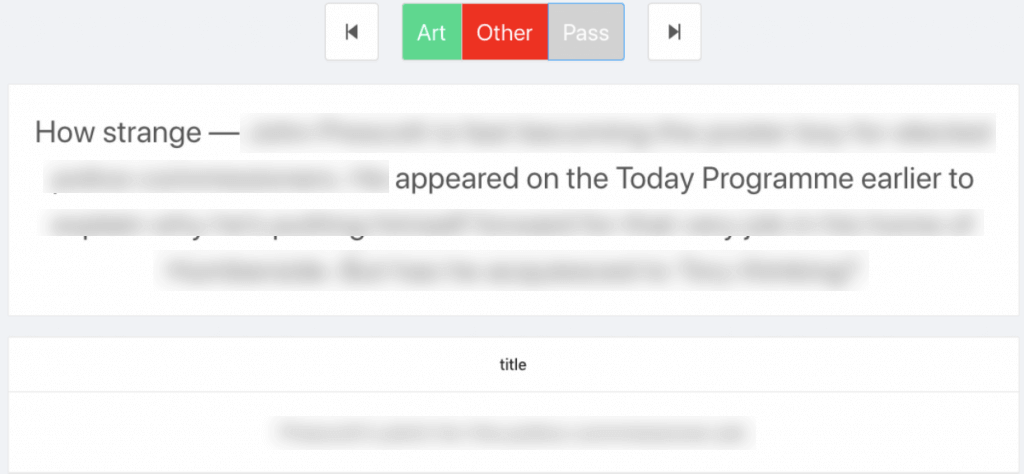
Evaluated the AI’s behaviour on unseen data
For qualitative analysis, Sculpt helped us visualise the model’s predictions on new data. Sculpt also highlights the main phrases that had a large weight in the model’s decision, which helped them make sure the model is making decisions using the correct criteria. Finally, we could see the model’s confidence (a decimal from 0 to 1) for each example.
 For quantitative analysis, Sculpt provides the precision-recall curve for each binary classifier, with its respective area under the curve (AUC). The Y-axis shows the model’s precision, and the X-axis shows its recall.
For quantitative analysis, Sculpt provides the precision-recall curve for each binary classifier, with its respective area under the curve (AUC). The Y-axis shows the model’s precision, and the X-axis shows its recall.
- Precision: the percentage of times the model is correct when it makes a positive prediction. For example, when the model says an article is talking about “Arts”, how often is it correct?
- Recall: the percentage of positive examples that the model detects. In other words, this gives us an idea of how much coverage the model has. Is the model missing too many examples?
- Area under the curve (AUC): it’s a decimal from zero to one representing the area under the graph. If we get a one, then it’s a perfect model. This gives us an overall idea of the model’s performance.
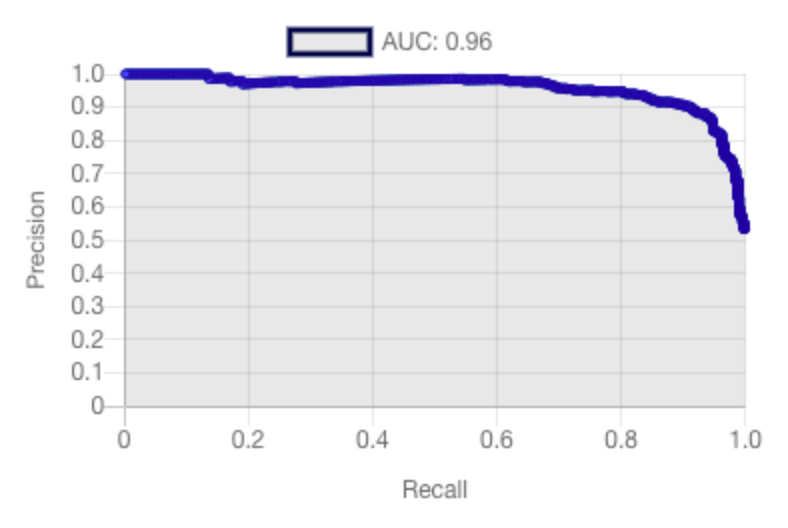
In machine learning, there’s always a trade-off between precision and recall, because a model could have very good coverage, but be making too many mistakes. On the contrary, a model could be correct on a small subsample of the data but miss many important examples.
Easily used the models
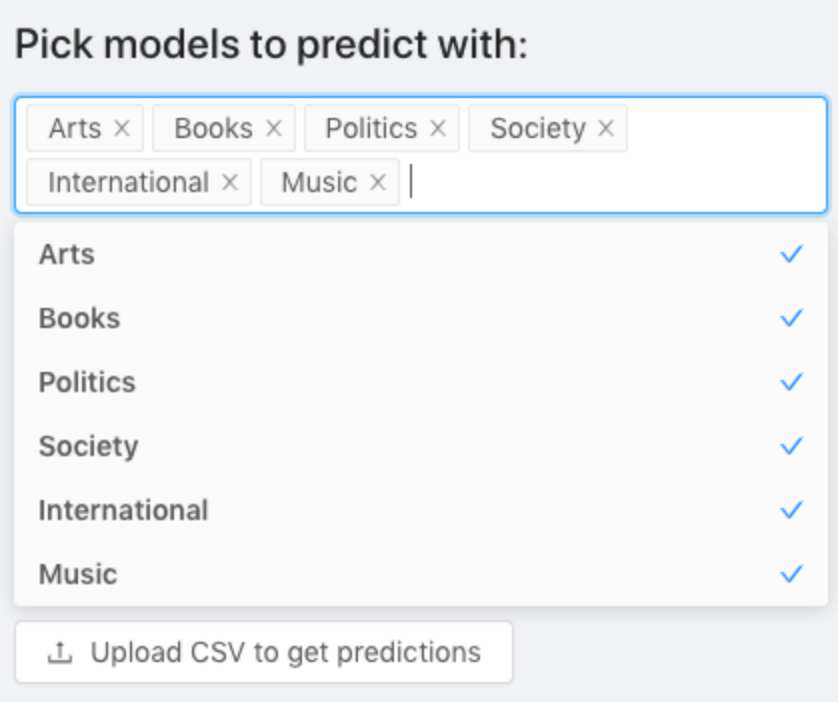
The last step was to combine the four binary models into one multiclass model, as explained in the previous section, and use it to classify 1M new documents automatically. To do this, we simply went on the UI and uploaded a new list of documents.
Sculpt did some computations and spit out the results, a CSV file with confidence scores for each of the categories we cared about, along with the news document URLs so that we could easily verify them. This is how we can quickly categorise 200,000 articles in less than 7 hours.


