How to easily map product redirects in ecommerce migrations
Two years ago I wrote an article called ‘How to deal with huge amounts of redirects in an SEO migration’, and with this we created a bulk redirect generator tool.
The original article was mainly based around the logic of a migration and it was more of manual ‘hands on’ approach, discussing things such as using filtering effectively, useful formulas, and identifying patterns.
In this article I am going to demonstrate how you can automatically generate almost all redirects for entire ecommerce migrations in almost any situation, whether it’s any of the below:
- Platform migration
- Domain name change
- URL restructure
The bigger the website is (let’s say 20,000+ pages), then the more value you will get from this method.
For the purpose of this article I will focus on one of the more difficult types of migration; a URL restructure as part of a platform migration.
Using unique identifiers to map redirects
The core concept behind this idea is that you are basically moving an inventory of products/items from one place to another, and there are some things about products that do not change during this transition. For example, unique product information like:
- SKUs
- IDs
- Part numbers
- Unique [product] names
This means that if we have a list of all product SKUs, and these do not change during the migration, then we can very easily map the old pages to the new.
One way to do this would be to request an export of the entire current product catalogue on whichever platform the website is on, and there will be a high chance that there is a unique identifier attached to a lot of these pages — let’s go with SKUs for the purpose of this example.
However, a common issue with this is that product catalogue/database exports don’t generally contain URLs and the SKUs together; it’s usually just the SKUs and other miscellaneous information.
Is there a more reliable way that we can get all this data ourselves, 100% of the time, without needing to rely on anyone else?
Extracting SKUs via XPATH
We can use XPATH extraction with Screaming Frog to crawl the website and our XPATH statements will extract the SKUs during a crawl, which will give us all the URLs matched to their SKUs:
- Use Chrome as your browser
- Navigate to a product page and right click on the SKU
- Click inspect element (this will open Chrome dev tools)
- Right click the element it takes you to and click ‘Copy > Copy XPATH’
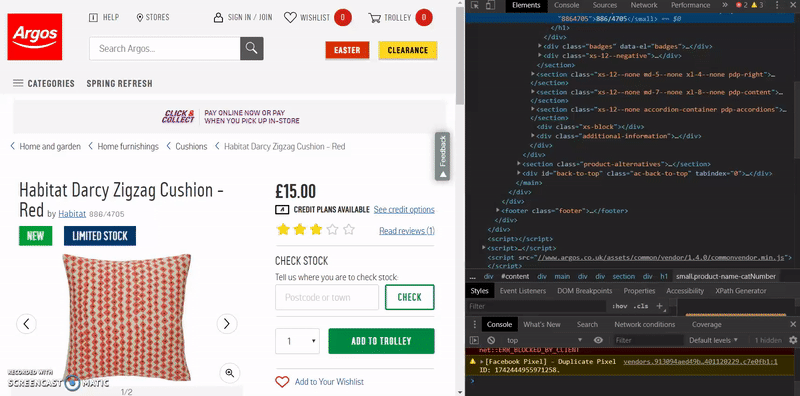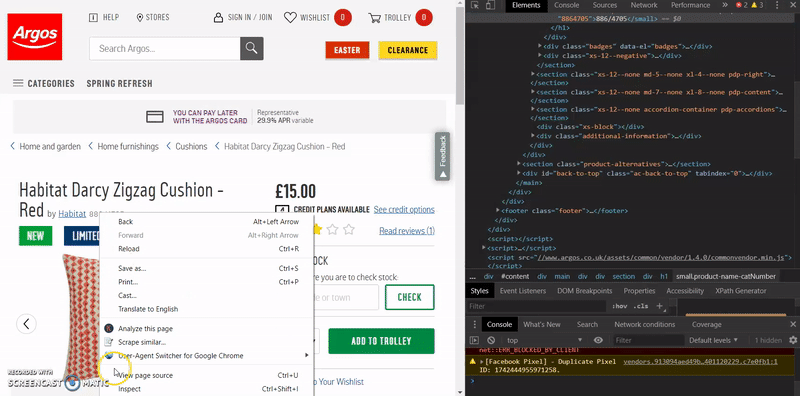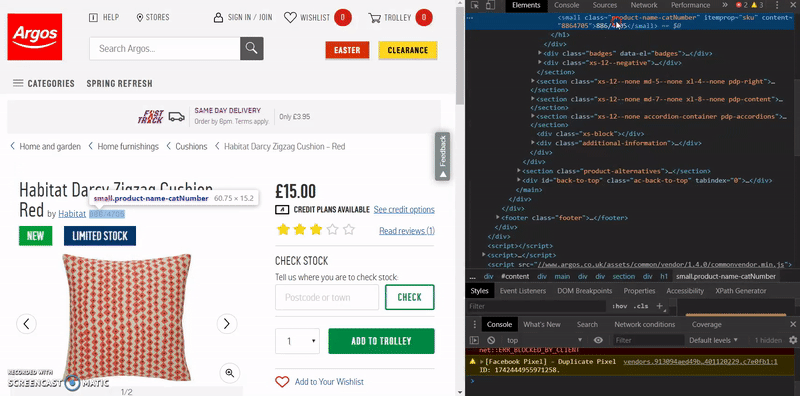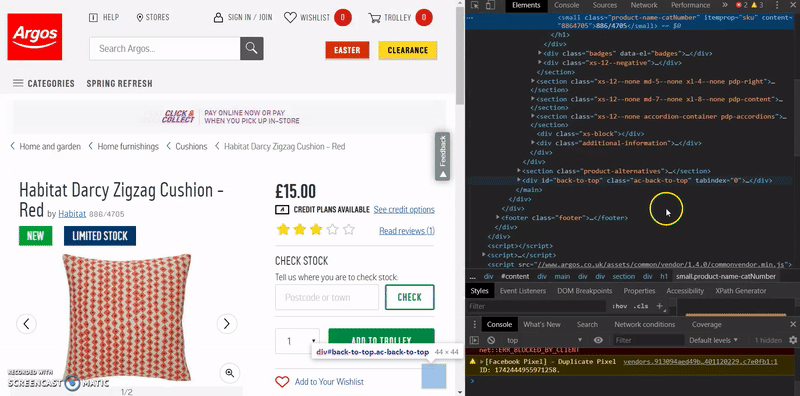
In most cases, this will be all we need and will work first time, however, if you find this doesn’t return the SKUs when you run the crawl, then it’s likely due to the way the website has been coded and you will need to try a few other methods to get the XPATH you want.
For example, there is a decent Chrome plugin called ‘XPath Generator’ which I have tested and I found it to be somewhat more accurate than copying the XPATH from Chrome DevTools.
If for some reason the website is coded in such a way that different product pages have different XPATHs, then you will need to identify these pages and make sure these XPATHs are being extracted (up to 10 can be extracted in one crawl).
It is rare that a website’s product pages will be coded differently though.
Crawling the website & collecting XPATH content
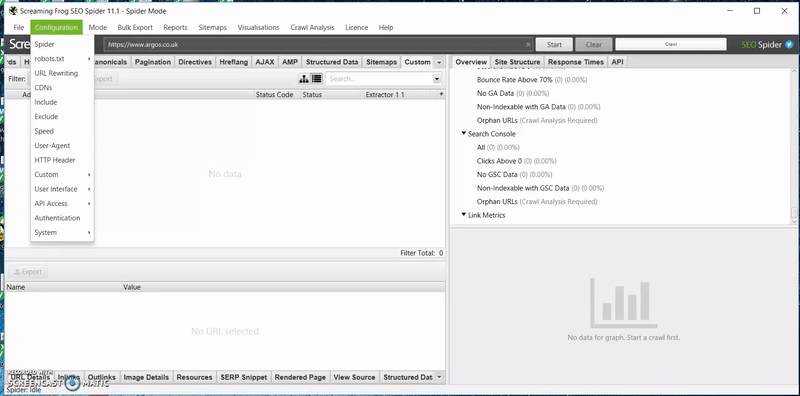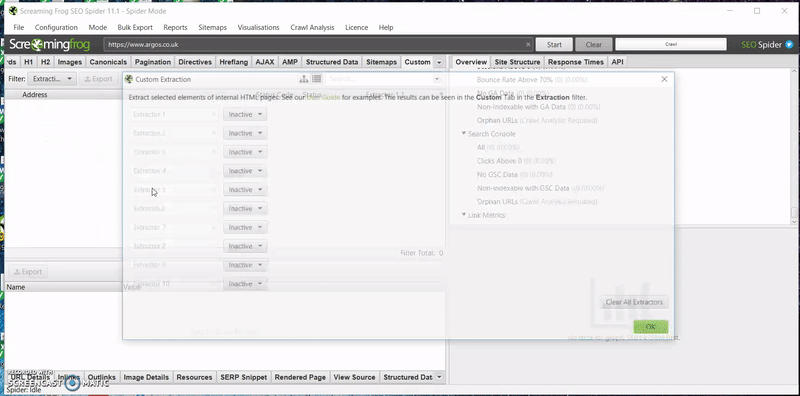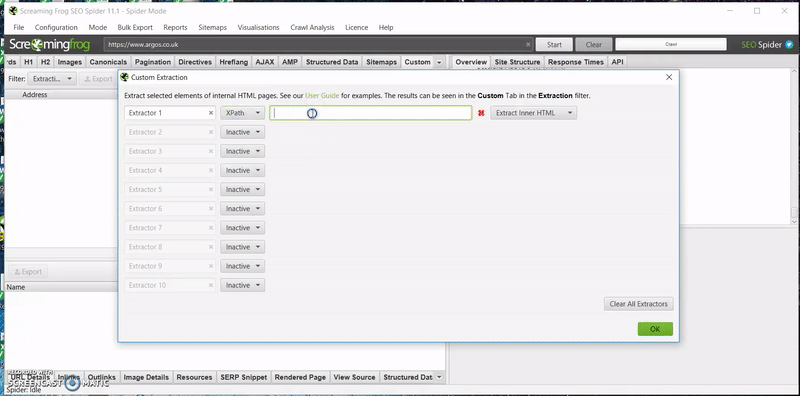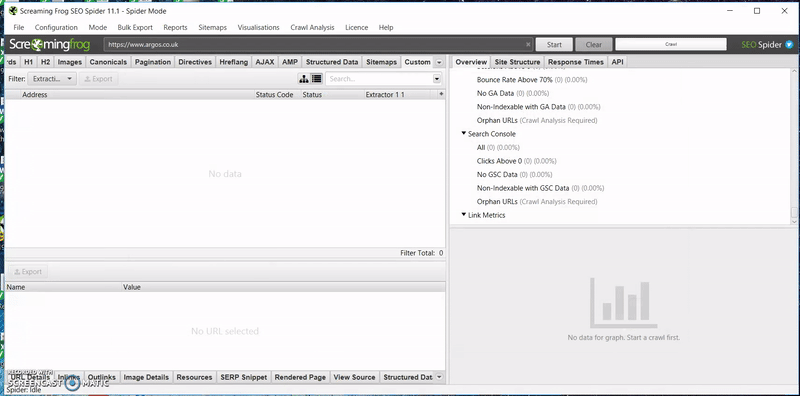
- Open Screaming Frog and go to Configuration > Custom > Extraction
- Change the ‘Inactive’ drop down to ‘XPATH’
- Paste the XPATH into the first field
- Start the crawl of the website
Assuming everything has gone smoothly, in the ‘Custom’ tab in Screaming Frog, change the filter to ‘Extraction’, and you should see something like this:
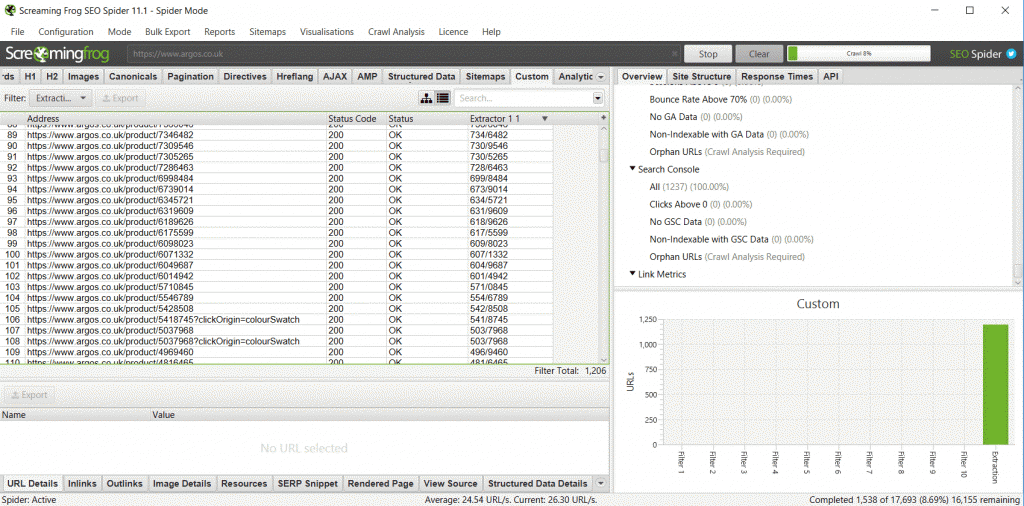
You’ll notice there’s another pattern here (an alternative way that we could extract the product SKUs, in this case), and this is because the product SKUs are always at the end of the URL on the Argos website.
This means we could do a normal crawl and extract the last part of the URL using formulas, but the XPATH method is much cleaner and works in all situations.
If you can see the XPATH you are extracting, and it matches the end of the URL (which is the SKU) perfectly, this is more like reassurance that everything is working as it should.
Creating the redirect mapping
Once the staging website is complete and ready for review, you can use the exact same method as above to extract product SKUs and their new location URL.
You’ll then have the two sets of data with the URL and SKU for both pre & post migration, ready to be put into Excel and mapped using a simple VLOOKUP formula.
For example, in tab one you have the ‘old URLs’ and SKUs, and in tab two you have the ‘new URLs’ and SKUs.
Next, in tab one you can perform a VLOOKUP or INDEX(MATCH) on the unique SKU on the data in tab two, to look for the same SKU and return the new URL.
Now you will see that all the old product URLs are now matched perfectly to the new URLs with one formula.
Categories, blogs, other informational pages
With all the product redirect mapping done, this should be about 75%+ of the work complete — but how do we do something similar for other types of pages that don’t have SKUs?
This is slightly out of the scope of this article, but I can suggest a few ways:
- With the products mapped, you’ll be able to clearly see the two URL structures and what (if anything) changes. This is extremely useful as you can then just do a bit of backtracking from the product URL and try to spot a pattern for the categories, etc.
- If any of the other pages have any unique identifier at all, whether it’s the <H1>, <title>, or a ‘hidden’ ID, then we can use the XPATH extraction method again.
- I have not explored the idea of injecting ‘hidden page IDs’ in to all pages of a website, but I’d find it very interesting to test out. This would mean that all pages have a unique identifier and all redirects can be mapped using the XPATH method. It would be a strategy that would have to be discussed at the start of the project and uniquely prepared for.
- Blogs tend to be easy to redirect as it’s very rare anything changes on them, so using some formulas to chop up the URLs you should be able to map the redirects easily.
Closing thoughts
This technique will most likely be very useful for very large migrations. For the times I have used this method, it has my life much easier, especially for ecommerce websites with 10,000+ pages.
There may be slight nuances each time you use this technique so you will need to be confident with using Screaming Frog, XPATHs, Excel formulas, etc., as you may need to make some small adjustments to make this method fit your project.
This method was inspired by how Salesforce Commerce Cloud (formally known as Demandware) handles migrations with its static mapping based around unique identifiers, which I am going to cover in my next article.
The main point of this article is to share a potentially great and easy way of mapping the redirects for all products in most ecommerce migrations to make everyone’s life easier.
I still think that this idea can be taken further, particularly by injecting hidden page IDs on every page of the website.
Check out our page on migrations, or contact us if you would like to see how we can help you with your site migration.


