Common Demandware SEO pitfalls and how to fix them
Being one of the main enterprise ecommerce solutions for large brands, especially in the retail sphere, there’s not an awful lot of SEO documentation for Demandware out there. I’ve come across a few at best. Perhaps this shouldn’t come as a surprise due to the small number of brands using it – no matter how significant they might be.
As a powerful, cloud-based enterprise ecommerce platform, the licencing fees could be costly. According to CPC strategy, a typical customer that boasts annual sales between $20 and $500 million, which is their target client, can expect licencing fees between $200,000 and $700,000 per year.
With the recent news of acquisition by Salesforce, it is safe to assume that Salesforce will be taking Demandware to the next level. Not only a ‘mere’ cloud-based ecommerce platform but an even more powerful marketing platform – kind of a morph between the two platforms perhaps? We can certainly expect an integrated sales & marketing platform in the future.
If you’re on the client-side and are looking to use Demandware for your ecommerce platform, you might also want to consider the additional cost for investing in an in-house developer, or train someone to tweak and work on the site. With the figures being quoted, it is understandable that access to the platform is restricted and that there is a dearth of SEO documentations about the platform.
At SALT, we have been privileged to work with many international SEO clients who are using Salesforce Commerce Cloud (formally Demandware), so I wanted to share some of the common pitfalls that exist in there and how to fix them. It’s not an easy ride we can tell you that, but hey, as Nietzsche said, what doesn’t kill you makes you stronger. So here are some of our top tips on overcoming Demandware’s technical SEO challenges.
Crawl and Indexing
URL Structure
If you’re frequently working with Demandware websites, you will agree with me in saying that a Demandware website is easily identifiable by its URL structure, especially the specific folder structure of /on/demandware.store/Sites-yoursite-Site/default/.
This folder structure is generally innocuous as it is largely used for user information or hygiene pages e.g. user account, password, wishlist, storefinder, gift certificate, etc. Therefore, in most cases, you don’t need to do anything about it. With that being said, there’s always one or two folders that will need consolidation either to the homepage or to other relevant pages.
However, to optimise crawl efficiency, save crawl budget and keep the site’s index tidy, we’ve blocked the folder structure from crawling and indexing in the robots.txt file. We’d caveat that, before you decide to block it in your robots.txt, you know the purpose of each folder and get the full list of respective sub-folders that reside within this folder structure from Screaming Frog. Double or even triple check the folder that contains JS or CSS files as disallowing that folder might affect how Googlebots render other pages. Don’t worry though, if you accidentally block any folder with JS or CSS files that are required to render a page, Google will tell you that from a notification on your Search Console. Make sure you keep an eye on it on a regular basis.
(blocking hygiene pages from crawling and indexing in robots.txt)
Top tip:
Ensure that your URLs don’t contain special characters, as this can create issues with the canonical link of the page. During a routine technical SEO audit that we performed for one of our clients, we discovered thousands of 404 pages with a ‘null’ string at the end of URLs. After some investigation, we learnt that these URLs were actually canonical URLs from product pages that contained special characters in the URL. In our client’s case it was quotes within the URL. This then resulted in the canonical URL equating to ‘null’ due to malfunctioning backend code and creating thousands of 404 pages as shown below:
How we’ve resolved this:
Set your site’s URL configuration through the Demandware URL rules. You can do this by going to:
Merchant Tools> Site URLs> URL Rules> and then select the ‘Settings’ tab, and click ‘Edit Rules’.
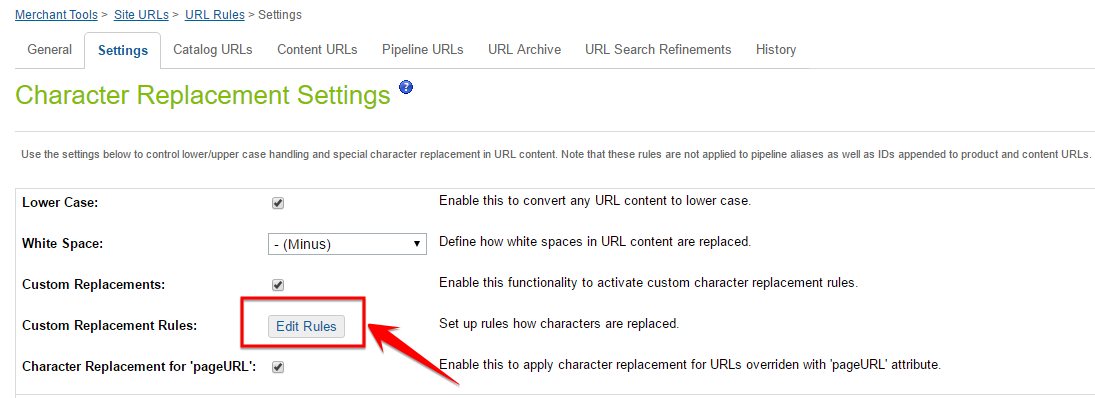
You can replace all special characters with blank so that it creates user-friendly and meaningful URLs, which in turn also resolves the canonical URL issues.
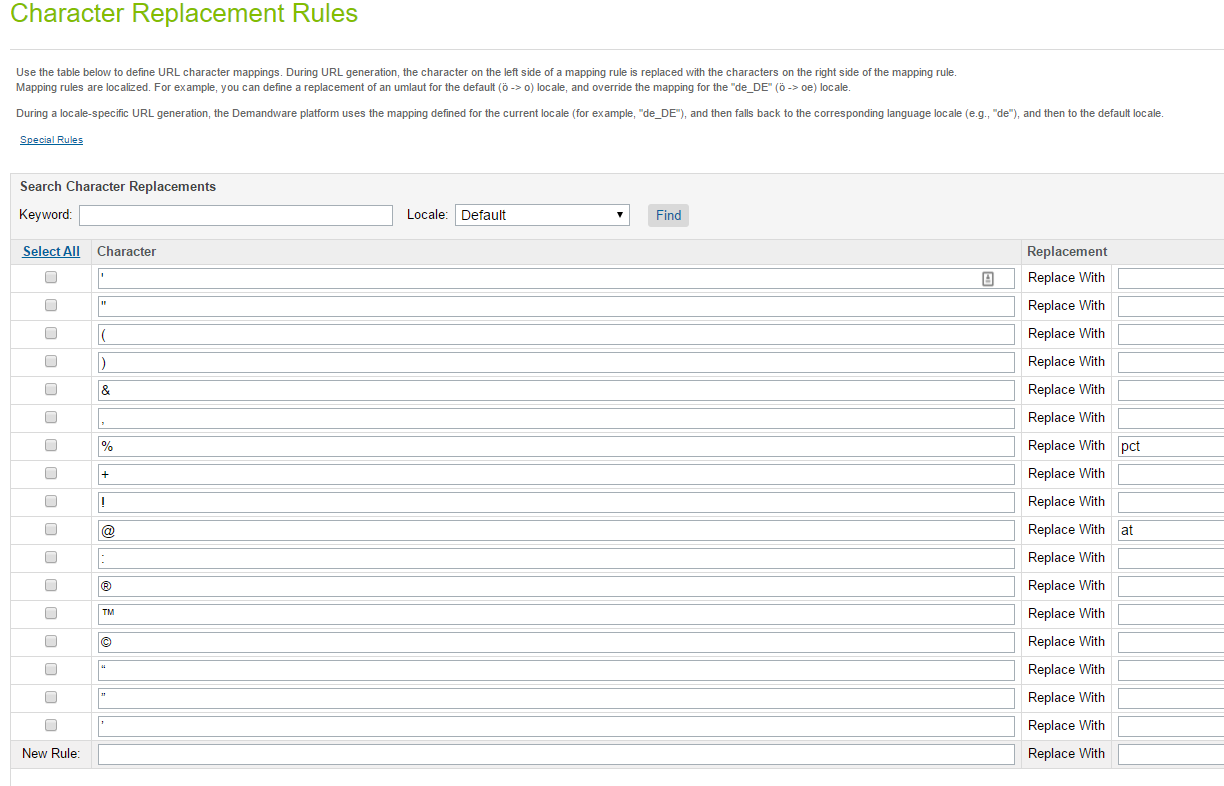
Robots.txt for Demandware (dev, staging, production)
By default, the robots.txt file for Development and Staging on Demandware is set to block all spiders to access any static resources, while for Production, it is set to allow spiders to access all pages.
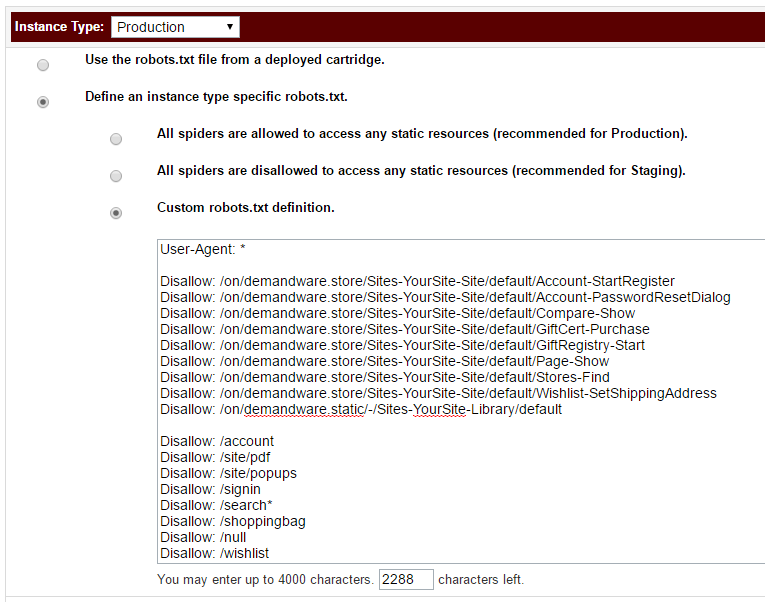
However, you can, and we urge you to, customise the robots.txt file and use it for Production:
As your business grows, your products and catalogues follow suit, or vice versa. This also impacts the number of user information or other hygiene pages, as well as category and product pages being created. Add the product refinement into that, which to be fair is one the fortes of Demandware but a complete pain in the backside for SEO, or a faceted navigation, where each product variation spits out URL with parameters. Then also add customised landing pages for your paid campaigns with all the UTMs and top it with international SEO country edition folders. Before you know it you have a colossal website in which the crawling and indexing can easily spiral out of control. Not to mention that there’s also a potential of content duplication issues
Therefore, having a customised robots.txt file for optimising your site crawl efficiency and indexing rate is absolutely crucial. Also, because Demandware hosts your website, you can’t have the server log file for analysis (a bit cruel if you’re rather OCD about crawl optimisation), which makes the role of the robots.txt file even more significant for your site organic performance.
URL with Parameters
Not only limited to Demandware but generally, URL with parameters are common SEO pitfalls and, if not handled properly, can cause all sort of technical issues from content duplication to crawl efficiency, or lack of thereof.
Even though Google is getting very intelligent about the handling of URLs with parameters, ergo URL duplication, it has, however, reiterated that you are the master of your own site’s destiny, or sort of.
Judging by the amount of resources Google’s put out there regarding duplicate URLs or URLs with parameters, hopefully you get the gist that it takes this thing very seriously. After all, duplication is a waste of bandwidth and resources so you can understand why it’s a serious matter for the search engine.

By default, product refinement on Demandware generates query strings of ‘prefn’ and ‘prefv’, so when you’re doing your regular site crawl with Screaming Frog, keep an eye on these two. Even though in most cases, these URLs with parameters are self-canonicalised to the primary URL, we’ve blocked them in robots.txt. Even blocking them sometimes doesn’t help as this doesn’t prevent URLs from appearing in search results. A quick site: search on Google will tell you that:
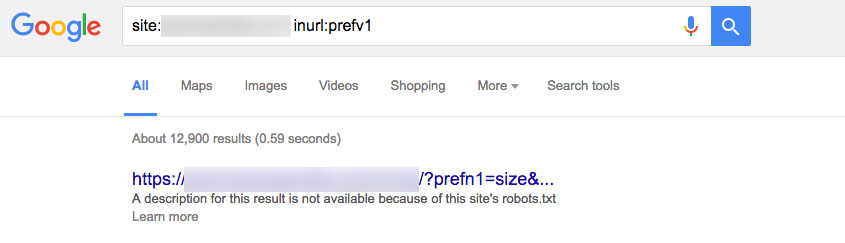
If your site has an internal search functionality and faceted navigation, a very mindful measure in how you handle these parameters is definitely required.
Tom Bennet has produced a solid, in-depth article in which, in one of the sections, he goes into detail about preventing search engines from discovering specific content on your website using various approaches. He further adds that the aims are twofold: to prevent these URLs from showing up in organic search results and to optimise crawl budget. Oliver Mason also did some testing on pairing Noindex with Disallow directives in robots.txt to get the indexed pages dropped out of Google index. What we’ve decided to be doing:
We implemented it in mid May 2016 and here’s what we’ve seen on Search Console:
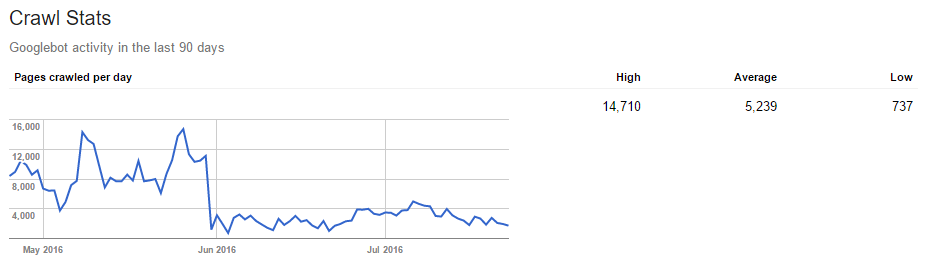
From our monitoring, we’ve also seen that the number of URL Parameters monitored by Google have been slowly decreasing over time. The latest figures indicate that the numbers have been halved compared to when we started working on the account.
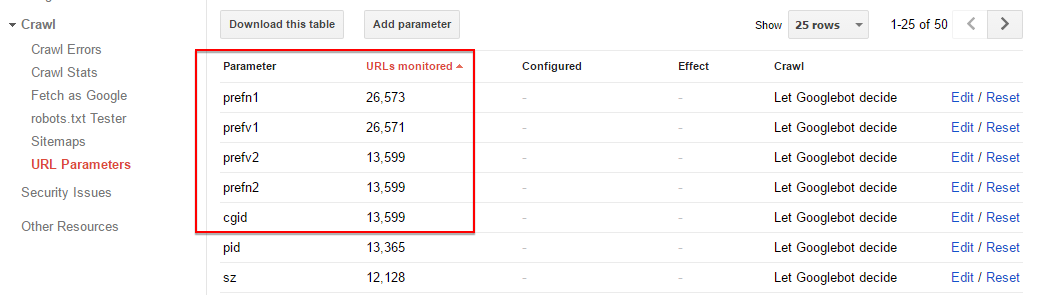
Whichever approach you decide to implement, you undoubtedly need to control how these parameters might affect your site’s crawl efficiency and the potential of content duplication issues.
404s and Soft 404s
First and foremost, it is worth bearing in mind that having 404 pages is an acceptable practice for an ecommerce website, particularly due to the nature of the seasonal product/category pages that are removed because they are out of season.
Naturally, you still need to keep an eye on the number of 404 pages on your Search Console and, following best practices, ensure that the 404 trend is showing downward trajectory. You can implement a 301 redirect but personally, I believe that 404 pages should not always be redirected if there’s no real reason to redirect them or no equivalent content to redirect them to. The page would be better served as a 404 page or even a 410 page. Only if there’s some sort of signal of quality pointing to a particular URL that is worth consolidation then you should be implementing a 301 redirect.
Issue arises when your custom 404 error page returns a 200 status code, instead of a 404 status code. Googlebots crawl the page and flag it as a soft 404 page. In general, soft 404s occur when: content on a page is an error page yet it’s showing 200, or content on a page is minimal and looks like an error page yet the page is showing a 200 status code, or content on a page is irrelevant to the original page (when a redirect is in place) – especially when implementing a catch all redirect to the homepage/category page.
It’s no secret that Google doesn’t like soft 404s; they’re bad for user experience. It can also hinder Google bots from crawling your site effectively and resulting in crawl budget wastage from Google bots as it is trying to crawl, identifies and index ‘non-existing’ pages.
On Demandware, you can spot soft 404 pages from a specific pattern on the page title. Usually, in the Screaming Frog’s crawl result, the page titles would look something like:

How we’ve resolved this:
- Determine if it’s worth your time to redirect the 404 pages or just serve a 404 page (effort/time vs. reward)
- Ensure that the custom 404 error page serves a 404 status code and the page conveys a clear message to the user that the page no longer exists plus some relevant links / search box to retain user on your site.
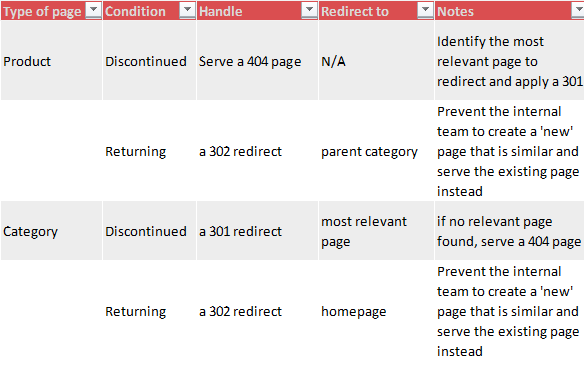
Our dev pipedream: develop a redirect functionality in the backend to handle different types of pages:
International SEO – Getting your head around multi-brand, multi-site, multi-arrrrRRRR
I must stress that this isn’t a common pitfall, at all. I’ve decided to include it here anyway because of the level of importance of it.
When using Demandware for international web builds, it is crucial to include SEO considerations at the earliest possible date. The reason being to ensure that the international versions of your site reside on the same codebase. In Demandware, you can share codes between multiple Demandware sites with Master Architecture.
In essence, Master Architecture means that there’s a core part of the codebase that applies to all or most of your sites. All site-specific styles and functionality are layered on top of that. The core part of the codebase will contain all of the shared features common to the multiple sites.
In one of our post site-migration audits that we performed for one of our clients, after they were migrating 10 European country TLDs to the .com TLD, we stumbled on an hreflang issue where the rel=alternate elements between the .com and other countries/language didn’t work. For example, a product page from the EN-US version isn’t associated correctly with the exact page from, say, the FR-FR or EN-GB version. As opposed to alternating among country editions, they are treated as separate entities/competing. The European versions, say, the EN-GB and DE-DE versions, are alternating just fine.
What happened was that the client development team had decided to build a different codebase for the US and the rest of the international websites. When the client decided to do the migration, the US and the European codebases were stitched together and it simply didn’t work. It took Google several months to understand the relation among country/language editions. Even then it’s still not working properly.
As touched on earlier, international SEO considerations are vital and the earlier this is taken into account the better it is to future proof your Demandware’s international SEO strategy. In many cases this means considering SEO best practice before any development planning takes place.
Quick SEO wins for existing Demandware sites
Quick Win #1 – Best Practice Document
Produce a document regarding on-page SEO best practice and how to handle a product or category page that is about to cease in its existence. This sounds very basic and is common sense, but ensuring that the internal team is aware of this is priceless and would undoubtedly save hours of resources, which can be put to good use elsewhere.
Quick Win #2 – URL Redirects vs. Static Mapping
If you’ve got tonnes of 404 pages, you can use the Static Mapping module in the Site URLs instead of the URL redirects module. Doing it this way will save your time on working on arduous, page-by-page manual redirects.
The way we did this was to put together a master spreadsheet containing all the 404 pages from all possible sources i.e. Search Console, Ahrefs, and Majestic, merge and purge the dupes and put a priority scale on which pages to redirect based on whichever metric you want. It could be the number of individual links pointing to the page, no. of linking root domains, social shares or any other relevant metrics. If you have thousands and thousands of 404 pages or want to fix broken links pointing to your domain to retain the equity, the Static Mapping module is a no-brainer.
Using Screaming Frog (I know, I know. I’ve mentioned it quite a fair few times but I do love the software!), make sure to fetch all the 404 pages’ relevant information such as status header, new redirect URIs, etc. before you are working on the 301 redirect. If the page has somehow been redirected to a new URI using a 302 redirect, then replace it using a 301 redirect instead. Also check for the redirect chain report from Screaming Frog in order to minimise the impact of link equity loss from the redirect loops. Small details matter and can win you big time in the long run.
Quick Win #3 – Page Load Speed
Minify the output code and remove unnecessary characters from the source code like whitespace, comments, etc. A reduction in source file sizes means a lower amount of data that needs to be transferred to site’s visitors and this in turn improves page load time/site performance.
Also double check the source code for a large number of inline JS/CSS/Base64. Unless necessary and unique, these codes should really be served async/from external files so that they can be correctly cached, thus, reducing page load times and improving page load speed/site performance.
You can work in reverse order and try to fix the speed performance on a page-by-page basis from your Google Analytics account by going to Behavior>Site Speed>Speed Suggestions and identify high commercial value pages vs. low avg. page load time pages and working your way down the suggestions listed there. Saying that, these are quite long winded steps, so it kind of defeats the point of it being a quick win.
Hopefully we’ve covered the most common SEO pitfalls when performing technical SEO audits on Demandware. That being said, if you’ve come across something that’s not covered here, or have some tips to share, I’d love to hear it!


