SEO Issues On Next.js Websites (50 Site Study)
Next.js is a popular component of modern headless architectures, with many companies choosing to build on the front end in Next.js and then connecting to a CMS such as WordPress for backend content management.
Like all platforms, these builds can have technical SEO issues, and this isn’t lost on Next themselves, who have built a technical SEO academy to address some of the common issues that can be found with headless, and JavaScript website structures.
Within the /learn/ space, there are a number of core technical SEO points covered, but what I want to know is how many websites being built using Next.js are taking notice of these elements.
To do this, I’ve taken a sample of 50 Next.js front-end websites from varying sectors, and tested them for:
- Core web vitals
- Status code returns (e.g. 404s)
- Use of canonical tags
As these are all covered in the Next.js SEO reading/learning literature as components of being good for search engine optimization.
Next.js & Core Web Vitals
Next make a point that “Google cares about giving users a fast and smooth result with great website experience”, and goes as far as quoting the “pass” thresholds from Lighthouse v6 for LCP and CLS, but also for TBT, which it aligns as a similar metric to FID.
So how many of the 50 websites achieve a “passing” grade for these metrics?
TLDR Analysis
- Only three of the 50 websites passed the LCP “good” threshold
- 42 of the 50 websites passed the CLS “good” threshold
- Only three websites from the 50 passed the TBT “good” threshold
- Only one website passed all three
To measure Core Web Vitals data for the 50 websites at scale, I utilized the Page Speed Insights API with Screaming Frog, and ran the crawl three times in order to establish an average score. This was to eliminate any potential false anomalies and skew the dataset.
One of the Next.js websites with the worst performance we looked at was TwoBird. On average, the homepage was registering a CLS score of 1.12 (substantially higher than the recommended 0.1), and you can see a number of visual shifts both on mobile and desktop when manually looking at the page.
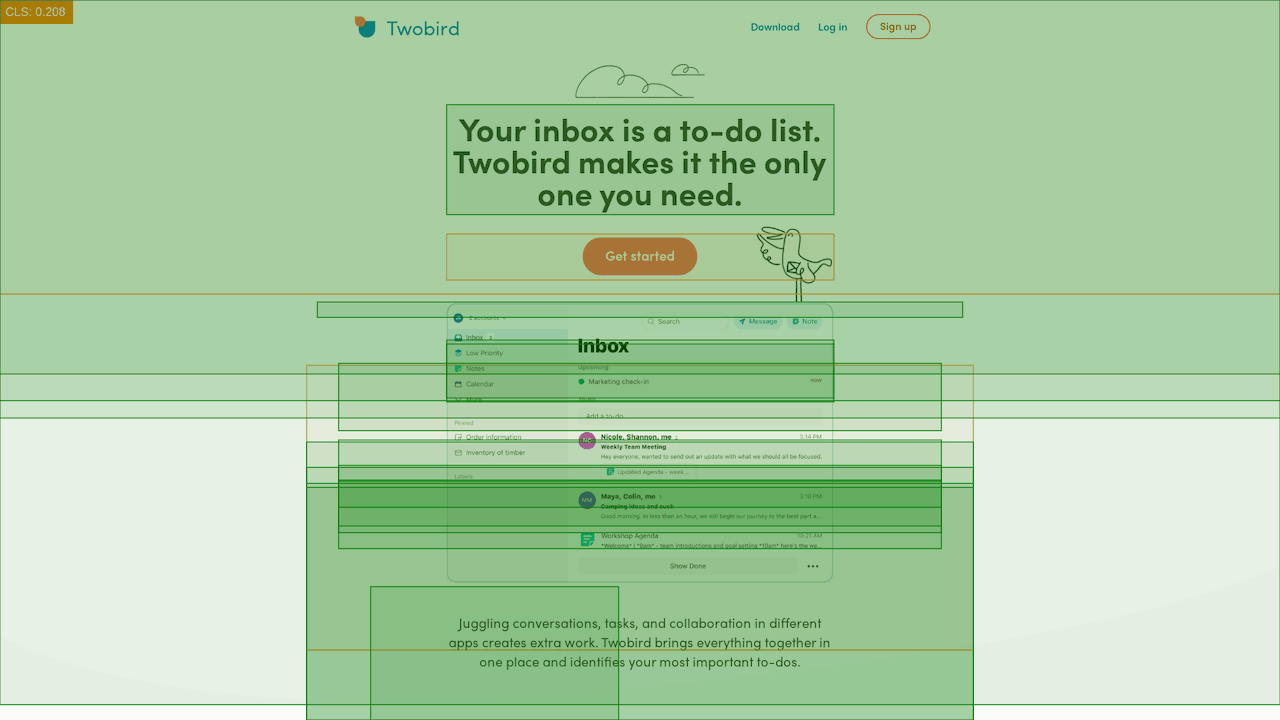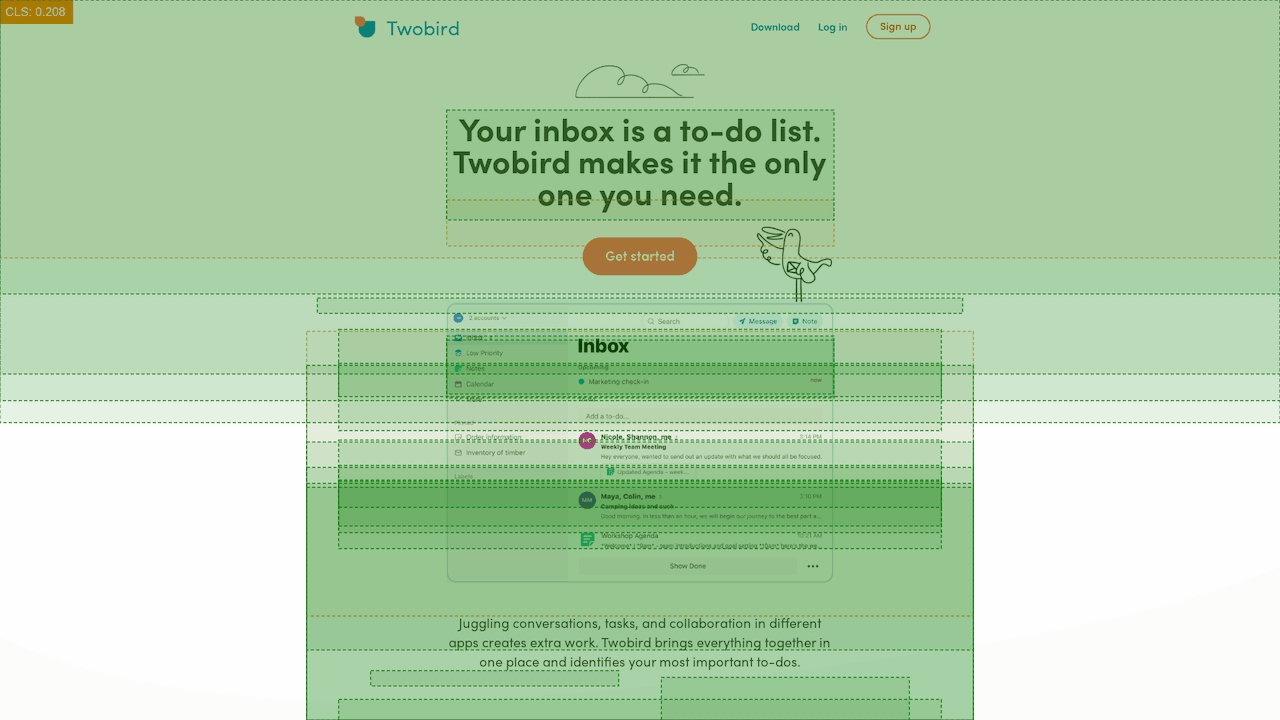
It is worth noting that Twobird only just failed the LCP tests, and passed TBT, so their issues look to be limited to visual stability.
The Next.js /learn/ literature emphasizes how visual layout shift can be negative for users, and for conversion rates/potential leads generated – citing a 2012 Amazon study that headlined with the notion that “one second” of page load can cost sales (in Amazon’s case, $1.6bn)
Error (Status) Codes
While HTTP status codes only affect the URL in question, when combined with other technical intricacies not handling them correctly can cause issues.
41 of the 50 Next.js websites analyzed don’t return 404 status codes for made-up URLs, and the nine sites all handle them in different ways.
In Next.js’ /learn/ section, they do state that:
Next.js will automatically return a 404 status code for URLs that do not exist in your application.
This then begs the question of why (if enabled by default) 10% of the websites choose to return 200 codes instead of the 404 (or alternative).
In fact, custom 404 pages on Next can be statically generated by creating a pages/404.js file.
From the nine websites that don’t directly respond with a 404, four redirect to the 404 page (three by 301 and one by 308). The end result is a 404 HTTP status code.
Four of the remaining websites return a customized 404-page template, but a 200 response code and Vercel.com return the login URL, with a ?next= parameter appended containing the “incorrect” URL string.
This isn’t necessarily an issue on its own, as you can use other directives for indexing control (such as canonicals, which we’ll come onto in the next section). But when you’re not returning canonicals at all – and returning 200 status codes for incorrect URLs – this can cause issues if UGC generates internal links for them or external websites points links to them.
Canonical Tag Usage
Out of the 50 Next.js websites reviewed, only 50% of the websites contained canonical tags.
While having a self-referencing canonical tag on all pages can be a technical “box tick” for most websites, it can be a useful tool in the wider scope that is better crawl management of the website.
For websites generating pages dynamically, non-mandatory canonical tags are recommended.
We have both anecdotal evidence for this, and snippets from John Mueller in a 2017 Google Webmasters Hangout (link).
As websites grow and scale, how Google handles canonicals on the site can be a good insight into where Google is perceiving site value and beneficial purpose. For example, if they choose to ignore the declared canonical and shows the message: “Duplicate, Google chose a different canonical than user”, this can help debug potential content/value proposition cannibalization.
If you’re interested in learning more about different site architectures, I recommend Reza’s article looking at Gatsby SEO, which is more of a JAMstack framework.


