An introduction to using XPath Extractions for SEO
What is XPath?
XPath is a query language that allows you to find the location of information within an XML document. This method makes it easier and quicker to look through a whole domain and output the required data in a systematic manner.
Although you may be using a crawler such as Sitebulb or Screaming Frog, using XPath allows you to search and identify specific content rather than exporting everything.
For this blog, I am going to cover a few ideas for when using XPath becomes useful with larger SEO tasks.
How to use XPath for SEO?
In order to start performing XPath for your SEO audits, you require some sort of program that can scrape XML documents.
Although I am going to include steps using Screaming Frog, it is possible to use Python, Excel and Google Sheets, and web browser plugins among other options.
To use XPath within Screaming Frog, go to the following:
Configuration > Custom > Extraction
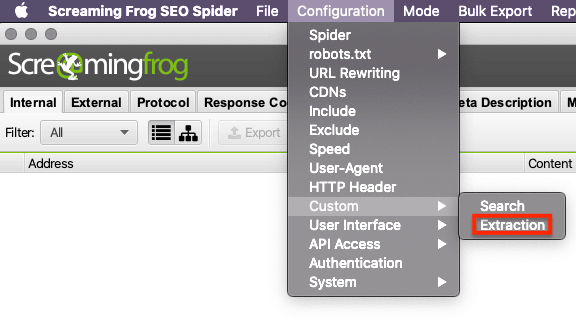
The new window then lets you set up and range of extractions, including CSSPath and Regex alongside XPath.
When the new window opens, add a line and select ‘XPath’ from the drop-down menu – it is possible to add multiple lines to perform multiple extractions at once.
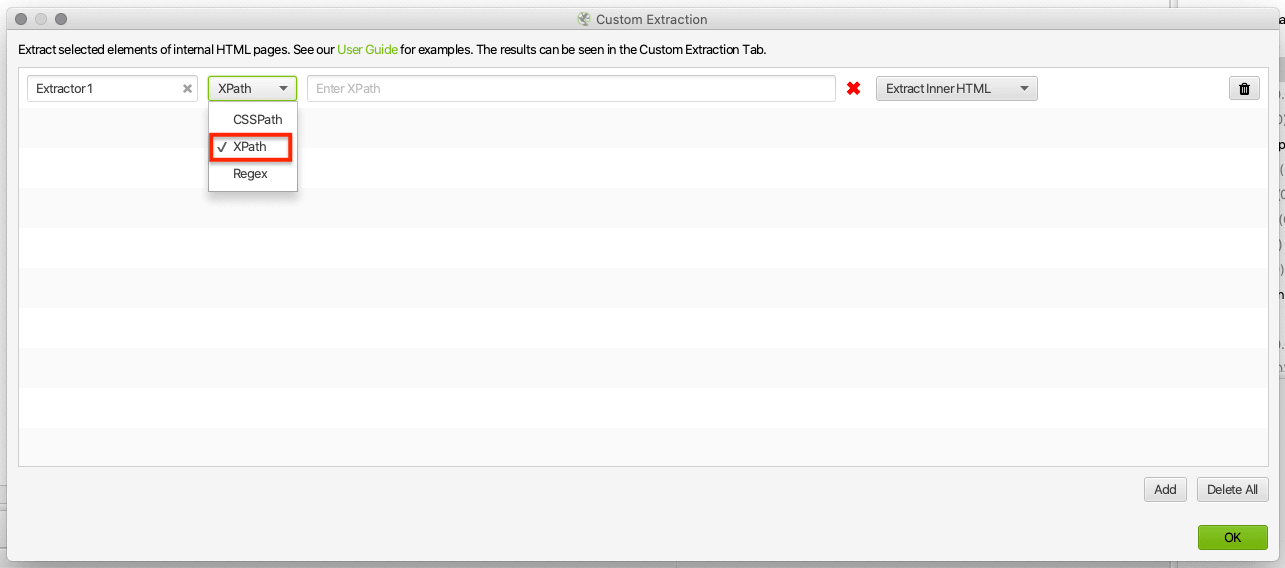
Select the data type you wish to extract from the right-hand drop-down.
It is possible to rename each ‘Extractor’ so that data is clearly labelled, although not mandatory.
Finally, you can add your XPath syntax(es) to perform your desired action.
Once your extraction(s) are set up correctly – as confirmed by a ‘green tick’ – you can then crawl the target website in list mode.
When the crawl is completed, go to the ‘custom extraction’ tab where you can view and export all the data.
XPath syntaxes
Performing XPath extractions can vary from basic to advance, as long as you know the correct syntax to perform the action.
Listed below is a list of some of the very basic XPath syntaxes with the outcome:

One of the easiest ways of finding an XPath Syntax is using the inspect tool in Google Chrome.
Find the element you wish to extract. Right-click and select ‘Inspect’ and then right-click the element and select ‘Copy > Copy XPath’.
In the below example, I have copied the XPath syntax from one of my previous blog post’s H1s, which I could then use to investigate H1s across the SALT.agency blog.
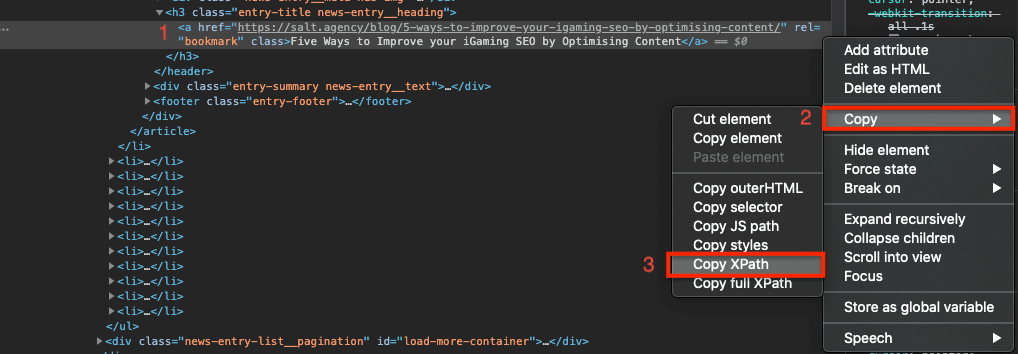
This then appears as:
//*[@id="post-4064909"]/header/div/div/h1
If I clean it up, it then becomes:
//header/div/div/h1
However, it is possible to perform more advanced syntaxes. Although this article won’t tackle any advanced extraction queries, there are many online resources that will help you perform complex problems.
Example 1 – Using XPath to identify internal linking opportunities
It is possible to use XPath to make even the most basic of SEO tasks easier and more strategic.
Take the challenge of internal linking. Although it is a relatively simple task and easy to implement on small websites, it becomes a lot more difficult on a website with lots of URLs.
Once you know which URLs, and hence the keywords you wish to optimise, you can include more internal links — you just need to find the opportunities and prioritise the pages that you include a link.
For example, if I wanted to find internal linking opportunities for the keyword ‘Internal SEO’ on the SALT website, I could use the following syntax query:
//div[contains(text(),"international SEO")]
Because I have copied the XPath query using Chrome inspect, I know to search the ‘div’ and have just added my query to search for the term ‘International SEO’.
Once I have a list of all URLs that feature the keyword, I want to get the ‘most authoritative’ pages to include a link to my target URL.
For this, I can then use an additional tool like Ahrefs’ site explorer to rank the URLs of my target site. Using a VLOOKUP with my exported Screaming Frog data set, I can prioritise my internal links and then go and implement them.
Example 2 – Updating XPath to identify old blog posts
If you have high performing blog posts that are bringing a lot of organic traffic to your site, you probably want to ensure that they remain updated.
To do this, you can use XPath to search for posts by publish date.
As mentioned above, find the date element, inspect and copy the XPath.
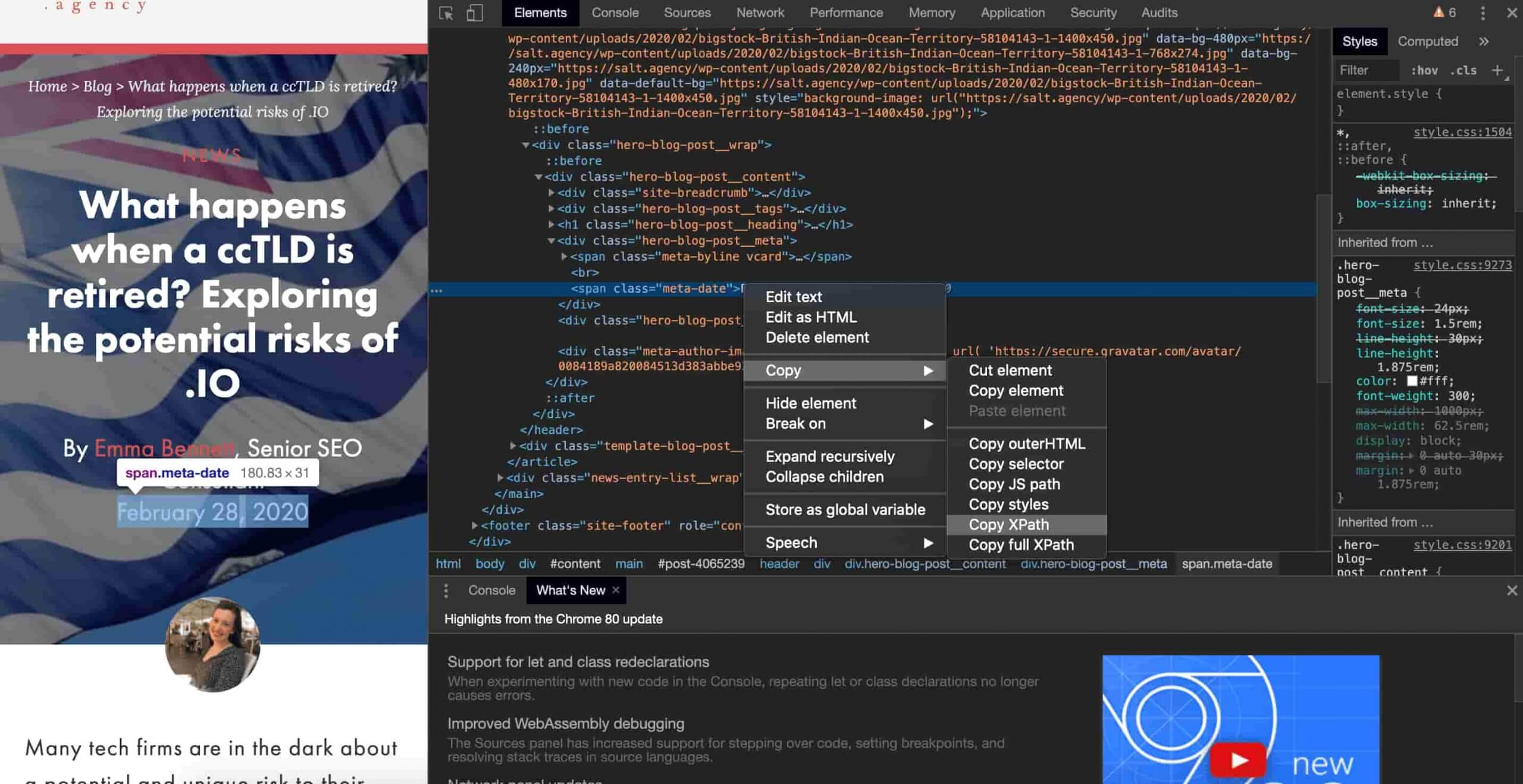
For this example, the following syntax is copied and cleaned up:
//header/div/div/div[3]/span[2]
You can either upload a list of your top-performing blog posts, or you can do a complete crawl as usual.
When I do this with the SALT.agency blog posts, I can generate a list of published dates with the URLs:
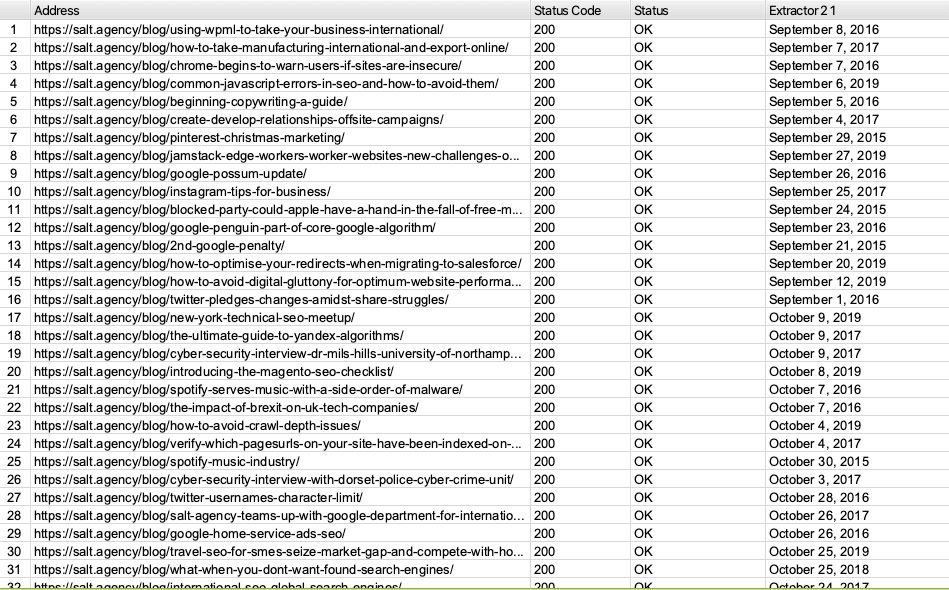
With another data source such as Search Console or Analytics, you can do a VLOOKUP to find which URLs you wish to optimise and prioritise on-page changes.
Example 3 – Using XPath to find featured snippet content
In a previous blog post, I have covered how Google looks at on-page data and optimises content for featured snippets.
There are three types of on-page elements that Google predominantly use for featured snippets; headings, lists and ordered lists.
Using Screaming Frog, finding H1s and H2s is easy. But it is possible to use XPath to find mark-ups for any remaining headers, right through to H6. It is possible to combine multiple queries using the ‘|’ symbol:
//h3|h4|h5|h6
Using the same method covered previously, the following syntax can be used for unordered and ordered lists respectively:
//div/div[1]/ul/li[1]/span //div/div[1]/ol/li[1]/span
Additional XPath Example
The previous examples of XPath mentioned above are relatively simple and are useful for SEO’s looking at using XPath for the first time.
For an additional example of XPath in action, my colleague, Aarron, has written about how you can use it on a larger scale when looking at migrating URLs on a large e-commerce store.


