Technical SEO for AI Search
For years, technical SEO has focused on making websites understandable to search engine crawlers. The landscape has shifted. Large Language Models (LLMs) such as ChatGPT, Gemini, Claude and Perplexity now play a growing role in how users discover and consume information.
This means technical SEO is no longer only about ranking in Google. It is about ensuring content is accessible, crawlable and understandable to a wider set of AI systems.
The following article is a summary of my talk from brightonSEO San Diego, if you would like a copy of the full deck – please reach out at [email protected].
Search engines are not the only crawlers anymore
Clients today want more than visibility in Google results. They want to appear in AI-generated summaries, conversational answers and citations within LLM responses. These tools behave differently to traditional search engines.
Many LLMs fetch content through simple HTTP requests, pulling raw HTML rather than rendering JavaScript or waiting for dynamic content to load. In practice they act more like basic scrapers than full browsers.
Some models, such as Google’s Gemini, do render JavaScript in AI Overviews and AI Mode. Others, such as Claude and Perplexity, do not. ChatGPT’s behaviour remains uncertain. This variation means technical teams need fallback approaches such as server-side rendering, static pre-rendering or compressed plain-text views tailored to specific crawlers.
Schema and Structured Data
A common question is whether LLMs depend on schema markup to extract and interpret content. Our research suggests that while schema is useful for Google, particularly in AI Mode and AI Overviews, most LLMs do not need it. They can parse text directly from the page.

This does not mean schema is irrelevant.
It remains important within Google’s ecosystem, and consistent structured data helps standardise content for machines. The difference is that LLMs will not ignore your content if schema is missing.
Robots.txt and crawling controls
Robots.txt brings added complexity. You may accidentally disallow LLM crawlers if your rules block other bots. Even if you allow them, your content could still be included in training datasets collected indirectly, for example through Common Crawl. The ccbot crawler is one of the most common sources of such data.
Blocking AI crawlers is not a guarantee that your content will be excluded. Allowing them is also no guarantee of visibility.
Site Speed and Core Web Vitals
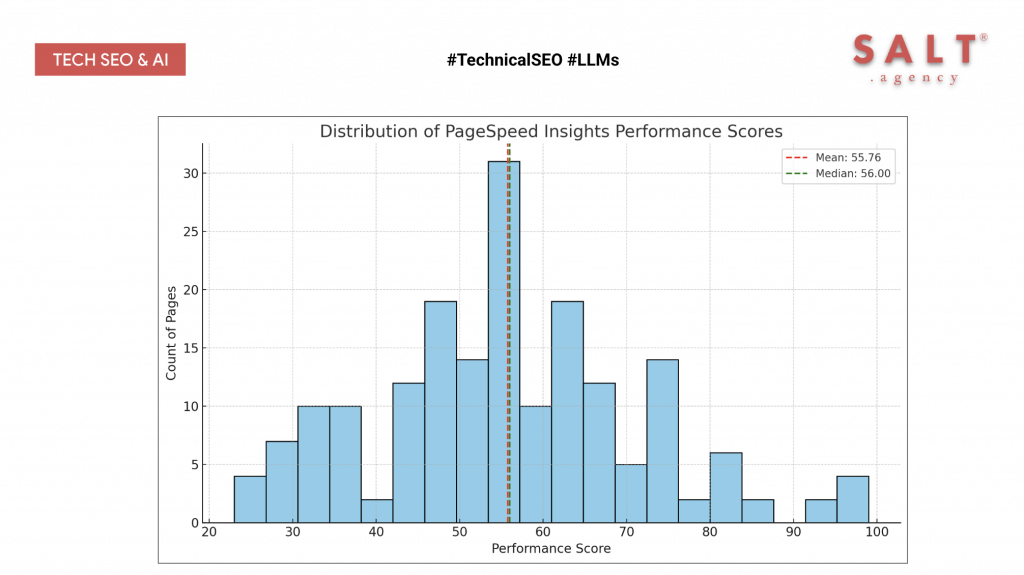
Performance is still a concern for visibility in AI experiences.
PageSpeed Insights scores are helpful for diagnostics, but the Core Web Vitals reflect user‑centred performance and are a better proxy for how easily crawlers and models can extract your content. Faster, stable pages are easier to fetch, parse and cite.
Data correlations from our study
From our analysis of 2,138 websites cited by AI tools, we observed a direct relationship between Core Web Vitals and visibility in generative answers.
These findings are based on our dataset and represent how technical performance influences inclusion rates:
- Sites with CLS ≤ 0.1 recorded a 29.8% higher inclusion rate in generative summaries compared with sites above this threshold.
- Pages delivering LCP ≤ 2.5 seconds were 1.47 times more likely to appear in AI outputs than slower pages.
- Crawlers abandoned requests for 18% of pages larger than 1 MB of HTML, highlighting the need for lean markup.
- TTFB under 200 ms correlated with a 22% increase in citation density, particularly when paired with robust caching strategies.
- Our study shows that performance improvements do more than enhance user experience. They directly increase the probability of being cited or surfaced by AI systems.
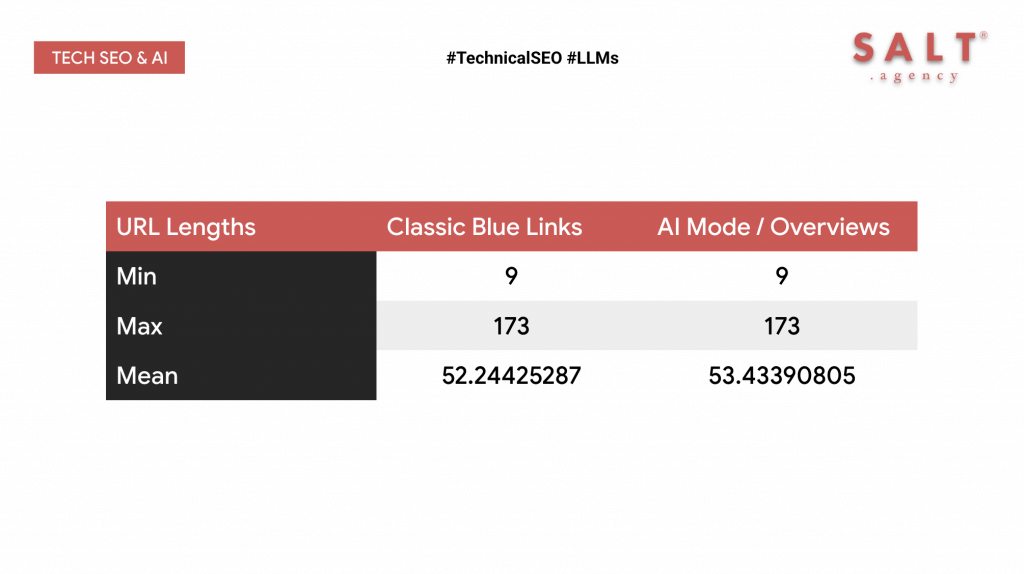
URL length
Our research also examined how site and page structure influences AI visibility.
From the same dataset of 2,138 websites, there were no discerning differences between the length of URLs in the traditional blue link results, and those cited in AI Mode for the same query set.
Page Structure and Pixel Depth
Our analysis also looked at how pixel depth (the vertical distance between key elements and the top of the viewport) influences inclusion in AI summaries.
The results show that the location of critical content within a page can significantly impact whether it is extracted by LLM crawlers.
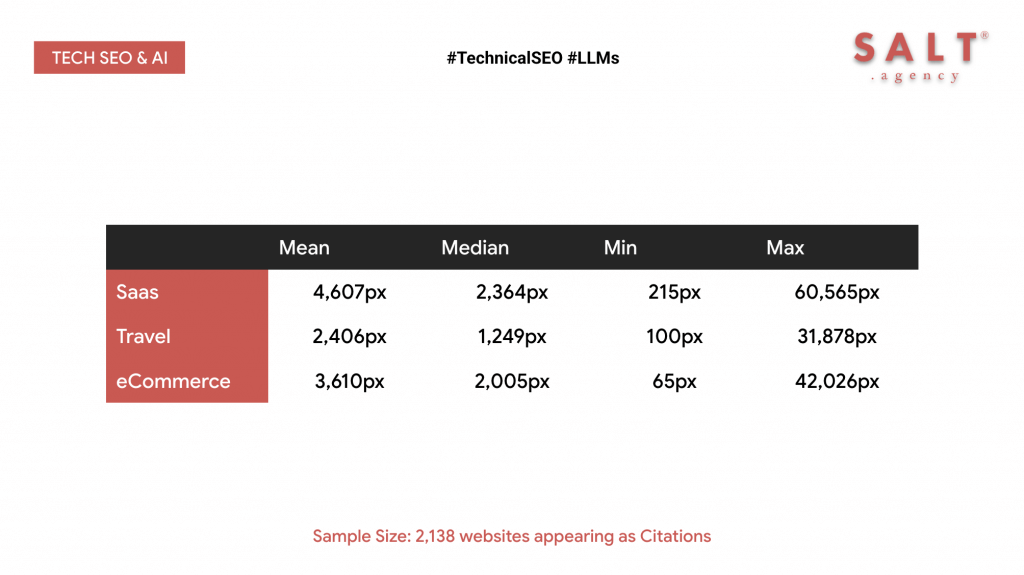
Main Content pushed far down the page by banners, carousels, or ad blocks correlated with lower inclusion rates.
This suggests that AI crawlers are sensitive to how quickly they can access meaningful content. While traditional SEO often tolerates deeper content as long as crawlers can eventually parse it, LLMs reward pages where key material appears quickly and consistently.
Takeaways
The foundations of technical SEO remain in place. The internet still has the same underlying structure. What has changed is the number and variety of crawlers interpreting that structure.
To stay ahead, SEOs need to adapt their technical practices to account for LLMs as well as search engines. That means:
- Ensuring raw HTML is clean and complete for non-JavaScript renderers.
- Considering SSR or pre-rendering for models that cannot execute scripts.
- Maintaining strong Core Web Vitals.
- Keeping site and page structures simple and accessible.
- Using schema where it matters, particularly for Google, while recognising it is not always essential.
JavaScript is once again a critical area for optimisation. The task now is not only to optimise for search engines but also for the growing ecosystem of LLMs that shape discovery and visibility online.
If you would like a copy of the full deck – please reach out at [email protected].


