A brief introduction to search engine information retrieval processes
In the early days of the internet, websites were just a collection of File Transfer Protocol (FTP) websites that users could use to upload an download HTML files.
In order to find a specific file, users had to navigate through each one, like finding a book in a library. Shortcuts did exist, and some frequent users learned the exact file addresses, or URI (unique resource indicator) of each HTML file they wanted or looked at regularly. This system assumed that the user knew what they were looking for, and had little room for speculative or research based queries.
In 1990, Alan Emtage of the University of Montreal created Archie, which we can consider to be the first search engine available on the internet — although by today’s standards, we wouldn’t class it as a search engine at all.
Archie downloaded a directory of all the anonymous FTP website documents and files from a given computer network, and stored them in a user-friendly, searchable database.
In 1991 the idea of Archie was taken one step further by Mark McCahill, who created Gopher. Gopher was a program that indexed plain-text documents, which later became some of the first websites publicly available on the internet.

Gopher however, created another problem as much as it solved another, users could search by document title but not by the contents of the documents. The solution to this came in the form of VERONICA (Very Easy Rodent Orientated Net Index Computerised Archive), and JUGHEAD (Jonzy’s Universal Gopher Hierarchy Excavation Display).
Both VERONICA and JUGHEAD worked in the same way and created plain-text indexes based on the content within the HTML documents being indexed by Gopher. This was the first step towards the search engines that we know and use today.
In 1993, Matthew Gray developed Wandex, which was the first search engine to combine both the functionalities of Gopher and one of the plain-text referencing programs into one.
Based on the World Wide Web Wanderer, Wandex was written in Perl script and for all intents and purposes, Wandex was the modern search engine usable for the World Wide Web.
Wandex was designed to establish the size of the internet, and the search engine functionality almost came as a secondary feature.
The methodology of online information retrieval and storage isn’t too dissimilar from the basis that all search engine crawlers work on today.
The first “full text” crawler based search engine however was WebCrawler, which was released in 1994.
The informational retrieval process
A search engine is a piece of software that uses custom applications to collate information (such as plain-text, page layout, meta data, external and internal linking structures), as well as other marked indicators as to the page’s content.
For an internet search engine, data retrieval is a combination of the user-agent (crawler), the database, and how it’s maintained, and the search algorithm. The users then views and interacts with the query interface.
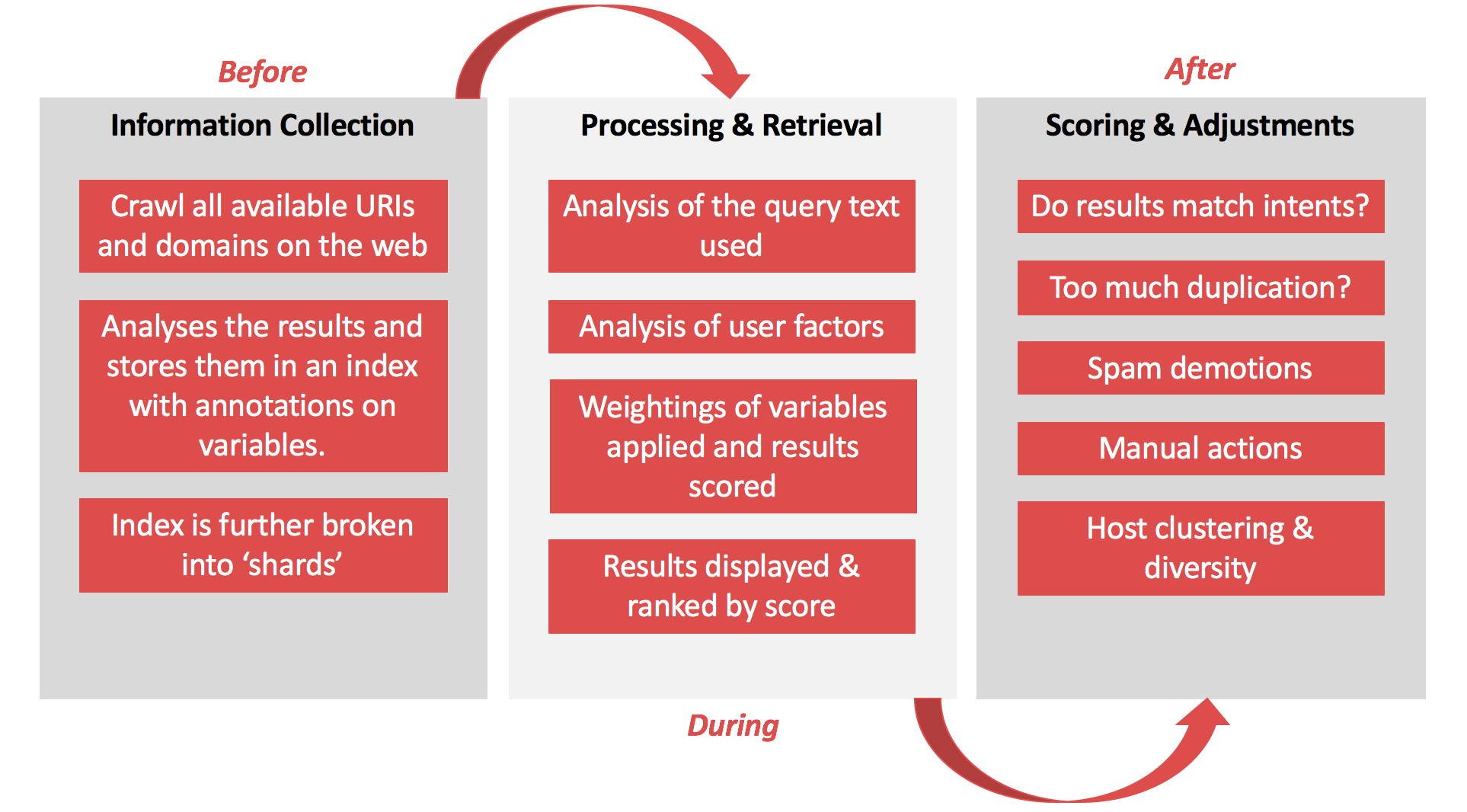
Following the production of a Search Engine Results Page (SERP), modern search engines (focused on providing a positive user experience), both validated and scrutinised the behaviour of users in order to improve user experience and results quality.
The user-agent
The task and processes of collating information is performed by a user-agent, that we call a crawler (or spider, or bot). The user-agent’s job is to identify and look at every URI and URL (unique resource location) on the internet, and extract the data.
A common misconception occurs here with the belief that every website has a defined “crawl budget”, when in reality, it has a crawl resource and a crawl limit, which can be used to manage and encourage crawling specific areas of your website (much like how a webmaster used to use the rel=”nofollow” attribute to sculpt PageRank to commercial pages.
Typically the more authoritative your brand is online and how competitive you are within your vertical (and how competitive and trafficked your vertical is), the higher your crawl resource and limits are.
The database
Every search engine user interface is connected to a system of databases, where all the information collated by the user-agents is stored. These are massive storage areas that contain numerous data-points about each URL, as search engines primarily operate on a URL by URL level.
In principle the modern day search engine databases are not too dissimilar from Gopher and Wandex, but the number of data-points and the ability of the user-agents to not only crawl but also render HTML documents has improved dramatically.

The algorithm
When SEO professionals talk about algorithms, it’s very easy to get sucked into the realm of talking about the named algorithms, such as Penguin, Korolyov, Pomegranate etc. In reality, search engines make multiple changes often on a daily basis that go relatively unnoticed by the wider search community.
In technical terms, search algorithms can be classified as list search, tree search, SQL search, informed search, or adversarial search.
Like a tree has branches that pan out, a tree search algorithm searches the database from broadest to narrowest, and vice versa. Databases are similar to trees and a single piece of data can connect to multiples of other data-points that are related. This is very much how the Internet is constructed, and is to an extent how linking works.
Tree searches are typically more successful for conducting searches on the web than some of the other processes, but they are not the only employed and successful informational retrieval process.
The query interface
On the front end of the application, the search engine has a user interface where they can enter a query and find specific information relating to what they have typed.
When a user clicks “search”, the search engine retrieves results from its database and then ranks them based on various weightings and scores attributed to data points on the HTML document. Modern search engines also apply personalised search aspects to queries as well, so ranking one to 10 is no longer linear or exact.
All search engines provide a different user interface and varying special content blocks. It’s also important to note in some cases that there are less then 10 “classic blue link” results on a SERP.
The user query interface is what 99 per cent of internet users think of when you talk about search engines, as it’s the page they interact with and take value from.
Query interfaces can come in multiple forms, ranging from the standard and simplistic search bar that a lot of us are accustomed to (e.g. Google), to more visual concepts (e.g. Bing), and very busy pages that act as information hubs without a query even being performed (e.g. Yahoo).
The fundamentals of search
It’s important to remember that as SEOs we’re not trying to gain advantage within Google, we’re trying to gain advantage in one of the most sophisticated informational retrieval softwares that has ever been created.
While we talk about technical being the core, the core is understanding how information retrieval works (as both a practice in computer science and library science).
By understanding this functionality we can understand how to create technically excellent websites before building the necessary signals for the target search engine to weight HTML document data-points in our favour (and give us higher rankings).


