Early testing of Google’s AI Mode
It’s been nearly a month since Google began rolling out AI Mode in the US., In typical Google fashion, a mix of curious screenshots has surfaced ranging from misinformation to completely random responses.
I’ve been focused on compiling and analysing as much data as possible from r early observations, aiming to understand the output and see how it correlates with traditional SEO metrics.
The hope is to begin building a clearer framework for how to track AI Mode moving forward. This will be especially fruitful if AI Mode activity eventually (hopefully) gets split out in Google Search Console alongside the present reporting inclusion that is blended with other Search data.
As with all observational work, results vary and individual experiences may differ.
We’ve drawn this data from a large sample size, though it does come with its own set of limitations and biases. I’ve tried to break down the methodology as clearly as possible and highlight the specific challenges we encountered while bringing the data together.
Thank you to Chris, Annija, and Peter for your work in compiling this data.
TLDR
- Sequential prompts generated more cited URLs than independent prompts.
- Comparison of traditional SEO metrics shows differences in ‘thresholds’ between sectors.
- Responses from AI Mode, generally, are similar to AI Overviews.
- AI Mode included shopping links without directly stating “Shopping” as a source.
- Some shopping result pages took 30 seconds to load compared to the usual 5–10 seconds.
- Shopping links included product details and identifiers (e.g., productDocid, catalogid, headlineOfferDocid).
Methodology
We analysed a sample of 588 prompts and question-style keywords across Travel, Ecommerce and SaaS sectors. These were tested in two ways:
- Standalone AI Mode chats with each prompt started in a new session
- Part of a sequential flow based on thematic clusters. For instance, if the queries focused on New York, they were kept within the same conversational sequence before moving to a new topic cluster.
Limitations
Due to the scale of testing, we encountered request limits which required changes to IP addresses at intervals. This was typically necessary every 50 to 60 prompts.
Measuring against traditional SEO metrics
As we continue transitioning from traditional SEO metrics to those more aligned with AI-driven search and large language models (LLMs), we’ve been analysing how Google selects and cites sources in AI mode.
To support this, we’ve reviewed 3,132 result URLs as part of an ongoing observational study, from 588 prompts.
We’ve broken down results by sector – Travel, SaaS, and Ecommerce – which helped identify subtle variations. It’s worth noting this is early data and findings may differ with broader sampling.
Our analysis focused on four key metrics:
- Domain rating
- Number of referring links to the specific URL
- Estimated number of keywords the URL ranks for on Google
- Estimated organic traffic.
All data was sourced from Ahrefs.
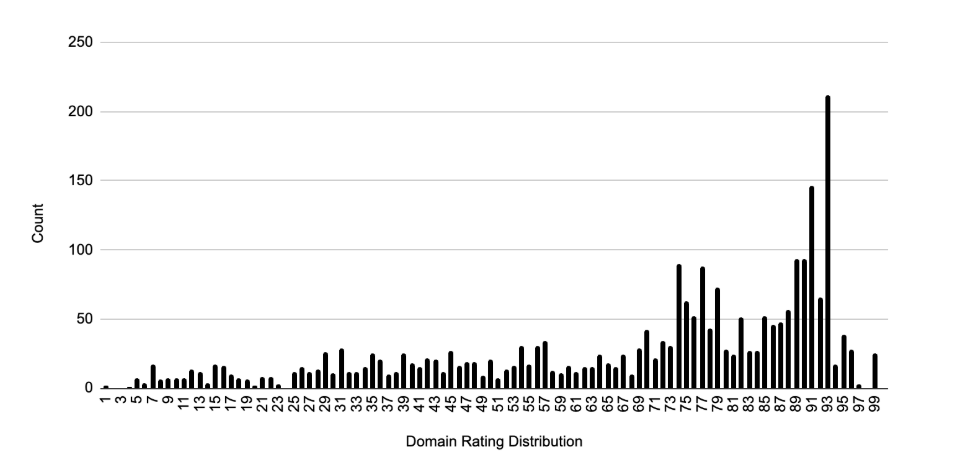
Domain rating
Domain ratings varied across the sectors. URLs cited in response to travel-related prompts had an average domain rating of 67.28.
Ecommerce prompts averaged 62.08, while SaaS and tech-related queries saw the highest average at 73.96. As expected, there’s a wide range in the data, so we’re working with mean averages for a clearer picture.
The graph visualises how often URLs fall within different domain rating ranges, highlighting the distribution across sectors and giving a sense of the spread and consistency observed.
Referring domains
Using the same three sectors and specific URLs from each prompt, we also looked at the number of referring domains per URL.
For Ecommerce prompts, the average number of referring domains was 22.
This rose to 35 for travel-related URLs, and climbed further to 88 in the SaaS and technology space. This upward trend reflects the generally stronger backlink profiles often seen in more technical or industry-focused content.
Traditional organic keyword visibility
We also analysed the cited URLs based on how many global keywords were visible in Google search.
Just as we’ve done with links and domain rating, this helped highlight the differences between the categories we examined.
On average, the URLs ranked in traditional search for about 471 queries. That figure rose to 648 for SaaS-related URLs and then jumped for Ecommerce, which averaged around 1,616 traditional search queries per URL. Across the entire dataset, an average of 911 keywords ranked per cited URL.
Traditional organic traffic
In the sample of AI Mode results we analysed, the average estimated organic traffic to each URL was 3,030.
Breaking this down across three sectors, Travel had the lowest average traffic per URL at 1,995. This increased to 2,817 in the SaaS and Technology sector, and rose even further in Ecommerce, where the average traffic per URL reached 3,480.
Independent versus sequential prompts
A key part of LLM-driven discovery is the emphasis on users engaging in sequential prompt conversations with these models.
In the past, I’ve described a similar trend in more traditional search behaviours, which I referred to as “query stacking” or early-stage exploratory searches. I’m expanding on that idea in this analysis.
What’s new with LLMs is the nature of the interaction. Users often begin with a vague or open-ended prompt., Then they develop it further, reshaping or refining the query based on what they learn or what feels more aligned with their intent.
This reflects a deeply human approach to exploration. It’s less about immediately finding the perfect prompt and more about evolving understanding through a back-and-forth exchange. That’s where LLMs differ significantly, there is a clear distinction between issuing isolated, one-off prompts and engaging in a sequential, adaptive prompting flow allowing for deeper discovery.
What is Query Stacking?
Query stacking is closely linked to early-stage searches, where users lack the right vocabulary or context to form precise queries. Instead of finding what they need with a single search, they build a series of queries, each shaped by what they’ve just learned. This iterative process helps refine their understanding and move closer to their goal.
It’s especially common when people are new to a topic and start with broad searches. As they gather more information, their queries become more targeted. With AI now placing greater emphasis on personal context, as seen in the recent Google I/O event, this kind of search behaviour is becoming even more important.
Though Personal Context wasn’t active during our recent testing, we examined how AI mode handles both standalone and sequential queries.
Comparing the two helped us explore how stacking affects the quality and depth of responses. It points to a shift in how users interact with search, and less about isolated intent, more about evolving through ongoing dialogue.
| Sector | Avg. Citations – Independent | Avg. Citations – Sequential |
| Travel | 9 | 10 |
| SaaS | 11 | 15 |
| Ecommerce | 9 | 13 |
More citations (on average) were present for sequential prompts. The top three visible citations on result load also differed substantially, with 94.1% returning different results or result orders, compared to independent searches.
Output comparison against AI Overviews
We’ve been living with AI Overviews for more than a year now, and experiencing the impact on clicks/organic traffic across multiple sectors. This led me to look at the output differences between AI Mode and AI Overviews across the 588 prompts.
To measure similarity, I’ve used a BERT-based text comparison.
Why use BERT?
Traditional text comparison relied on methods like TF-IDF or word overlap. These can capture surface-level similarity but often fail when the same idea is expressed with different wording.
BERT and its derivatives changed that. These models understand context, allowing them to generate embeddings (vector representations) reflecting what a sentence or paragraph actually means.
I ran this in a Colab Notebook, using all-MiniLM-L6-v2.
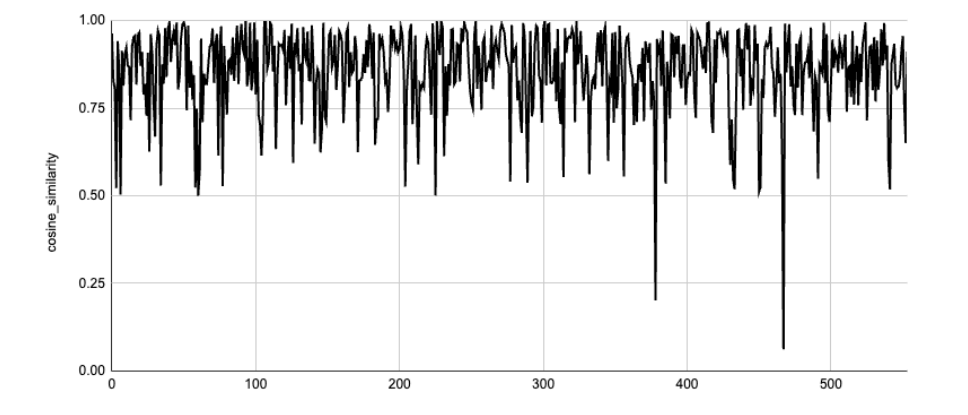
In our study, the resulting cosine similarity score was 0.84.
This is considered high semantic similarity, indicating both texts conveyed largely the same information even though their wording and structure differed.
A score like 0.84 suggests the two texts (AI Mode v AI Overview) could serve similar user intent or use cases, and can be treated as near equivalents.
Tracking traffic from AI Mode
One method of tracking traffic to your site from AI Overviews, and AI Mode, is the #:~:text= (hashtag colon tilde colon text equals) element in some referring URLs.
This isn’t foolproof. Our testing with AI Overviews shows not all citations include this fragment. The same is true for AI Mode. We found 1,806 of the cited URLs contained this URL fragment (57% of the 3,132), meaning under half of URLs cited (43%) don’t contain a distinguishing fragment for Analytics or Search Console to pick up.
Conclusion
AI Mode is still in its early stages, and while there is plenty left to uncover, our initial observations highlight some clear patterns and challenges.
From citation frequency to domain strength and traffic potential, it is clear that AI-driven discovery draws from similar signals as traditional search, though not always in predictable ways. The differences between independent and sequential prompts show just how important query context has become, both in terms of response depth and source selection.
We are seeing strong similarities between AI Mode and AI Overviews, but subtle technical behaviours, such as how shopping links are handled or how traffic can be tracked, suggest this is a distinct layer worth monitoring on its own terms.
As AI continues to shape the way users interact with information, being able to track and interpret this new mode of visibility is going to be important for SEOs and content creators alike.
This is just the beginning. There is a long road ahead in building out frameworks and tooling that can keep pace with how search is evolving, but we hope this gives you a useful head start.


