Canonical issues in Google Search Console and how to solve them
What’s a canonical URL?
A canonical URL is a way of publicly specifying your preferred version of a URL to prevent potential duplicate content issues, which may negatively impact your SEO performance.
If your website has a piece of your content that can be accessed via various URLs, the implementation of a canonical allows you to declare the ‘master’ version of your content. Although it’s only a hint and not a directive, it will be strongly considered by Google alongside other signals (site’s preference and user’s preference factors) when a page is assessed for its relevancy to appear in SERP.
Site’s preference factors include:
- Link rel=”canonical”
- Redirects
- Internal linking
- URL in the sitemap file
- HTTPS > HTTP URLs
- “Nicer”-looking URLs (user-friendly)
- Content quality
Staying consistent across the whole website will strengthen the site’s preference signals and increase the chance of having a page with user-declared canonical indexed.
How to implement a canonical URL?
Correct implementation of a canonical link will limit the number of potential issues affecting the website in Google Search Console and give you more control over which URLs appear in SERP.
Here are some best practices for implementing a canonical URL:
- A canonical link <link rel=”canonical” href=”https://www.example.co.uk”> should be implemented in the head of an HTML page.
- For PDF files, use HTTP headers to mark up the canonical version of a document.
- Use an absolute path. Google advises using absolute paths for rel=”canonical” tag.
- Ensure the canonical is indexable.
- Avoid JavaScript injected rel=”canonical” tag.
- If your tech stack can only support JavaScript-injected canonical tags, ensure only one canonical is specified in the DOM and is consistent with the canonical declared in the page source.
Common mistakes with canonicals
Missing canonical link
Suppose a page does not have a canonical link specified (either self-referencing or pointing to a master version of the content). In that case, Google will find the best canonical link for the page, which may not be the right one.
To help prevent incorrect URLs from being indexed as the preferred page version, ensure each has a canonical link implemented.
To find missing canonical links, use a crawler to extract pages without a canonical.
Canonical link placed outside <head>
A HTML canonical link needs to be placed in the <head> of a page. If it’s placed in the <body> it will be ignored.
For spot checks, use DevTools and manually search for canonical links. For bulk checks, you can use a crawler such as Screaming Frog and configure the crawl to search for canonical links in Head only. By cross-referencing all pages against pages with canonical link in the <head> you can identify incorrect implementation in bulk.
Multiple canonical links
Each crawlable page should only have one canonical link. If a page has multiple canonical tags, then Google will typically ignore all canonical declarations.
Canonical link is blocked by a robots.txt directive
To fulfil its role, the canonical link needs to be indexable. If a canonical link is being blocked by robots.txt, it can’t be crawled, preventing Google from ‘seeing’ the canonical.
Google will ignore the user-declared canonical and may choose a different URL, resulting in pages being ignored.
Canonical link returns non-200 status code
Using a non-200 (OK) status for a canonical link, such as a 404, prevents Google from ‘seeing’ the canonical. Google may ignore the canonical and index and rank a different page than desired.
Canonical link has a ‘noindex’ tag implemented
Implementing a noindex tag for a canonical link prevents Google from indexing its contents, and Google may ignore the canonical link altogether and index an entirely different page.
Canonical link chain
Canonical link chains happen when a specified URL has a canonical tag to a different page, causing a chain of canonicals for search engines to follow. Search engines can ignore canonical tags if they follow a canonical chain.
Canonical link mismatch
This happens when the HTML and rendered DOM canonical links do not match, caused by JavaScript updating the canonical to a different URL than the one specified in HTML code. As the signal sent to Google won’t be unequivocal, it may confuse Google and lead to an incorrect page being chosen as the canonical.
Canonical link is an isolated page
If a URL tagged as a canonical of another page can only be found via the canonical link and no other incoming links pointing to it, it indicates that the chosen canonical is not a part of the overall site architecture that users should access. Since the ‘site’s preference’ factors and user-declared canonicals are contradicting, Google is likely to ignore the canonical and flag the issue in Google Search Console.
Google Search Console canonical link issues
To find more information about the canonical-related issues discovered by Google, navigate to Google Search Console. If your website does not have an account set up, go to Google Search, create an account for your website (domain or URL prefix), and verify your property to monitor, maintain, and troubleshoot your site’s presence in Google Search results.
To find canonical issues affecting your site, navigate to
- Your property within GSC
- Indexing
- Pages
- Page Indexing
- Why pages aren’t indexed
- Page Indexing
- Pages
- Indexing
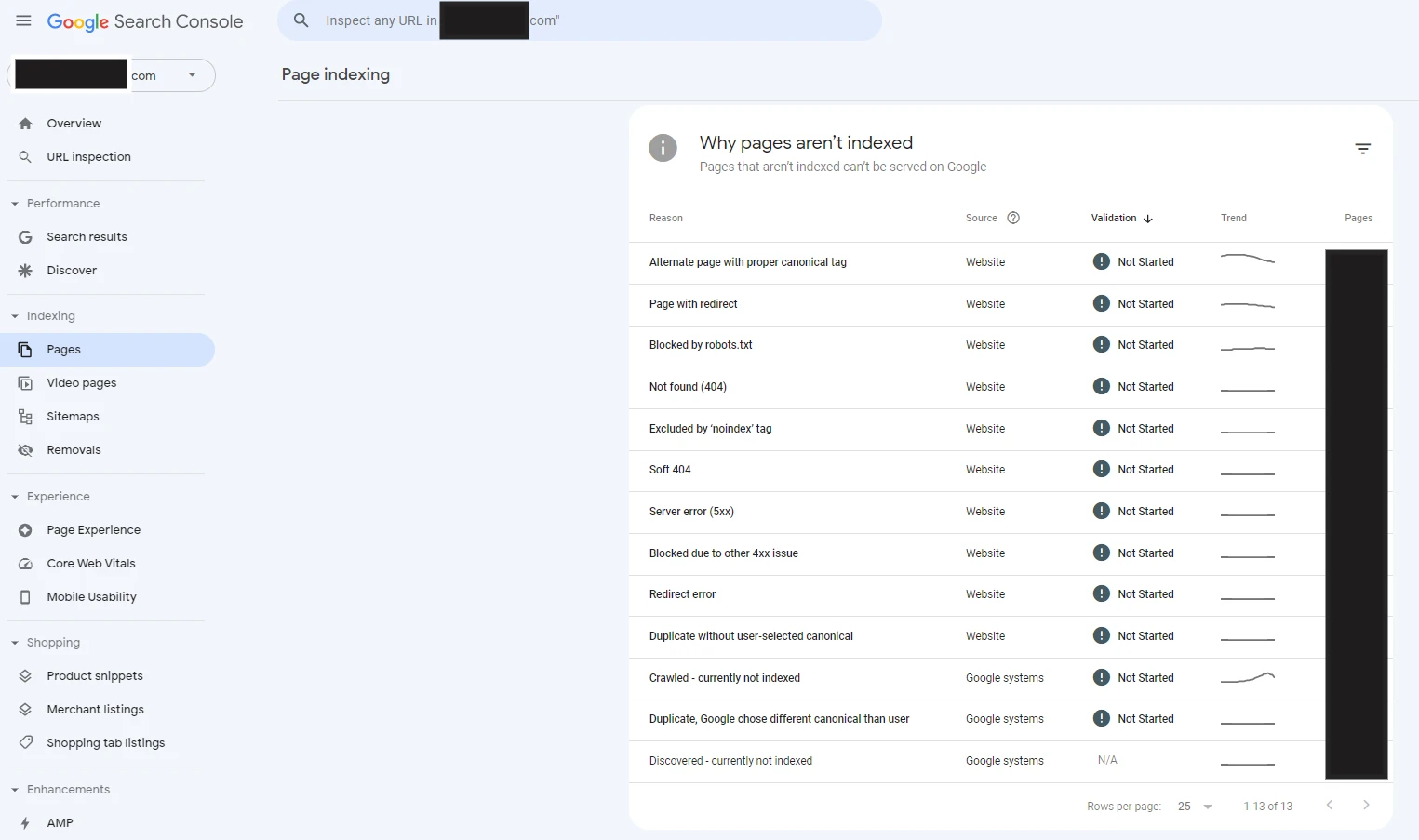
The ‘Why pages aren’t indexed’ section provides details about the reason a page is not being indexed, the source of the issue, the validation (Not started, Started, Passed), the trend (number of URLs affected), and the pages (number of pages affected by the issue).
To investigate in more detail which pages are being affected by a given issue, use the reason section to navigate to an issue you want to work on. The new screen will provide information such as:
- when the issue was initially detected
- the number of affected pages and the trend
- examples of affected URLs and when they have been crawled.
The drop-down option also allows you to view the URLs affected by certain issues by a source, such as:
- all known pages
- all submitted pages
- unsubmitted pages only
Canonical-related issues visible in GSC:
Alternate page with proper canonical tag
The message may occur when you’re using the rel=alternate tag to inform the crawler about alternate versions of a page, such as an accelerated mobile page (AMP). The message may be triggered when the canonical version of a chosen page has been indexed and not the page itself, such as:
- an AMP page with a desktop canonical
- a mobile version of a desktop canonical
- a desktop version of a mobile canonical.
How to resolve the ‘alternate page with proper canonical tag’ issue?
If your URLs are being marked up with this issue, review the URLs to ensure that this is the appropriate behaviour and that they should not be indexed.
Duplicate without user-selected canonical
Google highlights where it thinks a page is a duplicate of another. It does not, however, always make an accurate judgement, and pages may be marked up as duplicates if they are almost the same, as well as direct duplicates. Make sure to investigate if the ‘duplicate without user-selected canonical’ is warranted before any further investigation takes place. To investigate which page has been chosen by Google as the canonical, use the Inspect Tool within GSC.
How to resolve the ‘duplicate without user-selected canonical’ issue?
Canonical chosen by Google and your preferred page are uniform
Once you confirm the canonical chosen by Google is the page you perceive as the preferred version, there’s no pressing action required, though it is best practice to declare a canonical.
Canonical chosen by Google and your preferred page are not uniform
If the canonical chosen by Google is not the right page, ensure you explicitly mark the correct canonical for your page.
The page’s content is not a duplicate
If the page is not a duplicated version of another page, make sure the content served across those pages is unique and differs significantly from each other. Google may choose a different canonical to the user if the canonical link has not been implemented properly, if Google thinks there’s a better URL that could be served as a canonical, or other ‘hints’ that indicate which page is the preferred version.
Why would Google chose different canonical than user?
This might happen if the URL in question has been marked as a canonical for another page, but Google thinks that a different URL is a more suitable master version of that page.
Let’s consider a comparative example:
- Page A – User-declared canonical (Page B)
- Page A – Google-preferred canonical (Page C)
In the example above, Page C will be indexed, as it has been chosen by Google to be more suitable.
If Google ignored a self-referencing canonical, ensure that your page’s content is unique and has a sufficient number of incoming internal links. If a canonical URL pointing to a different page has been ignored by Google, ensure that the content of the pages is individually unique to increase the chances of Google following the indicated canonical.
Alternatively, update the canonical URL to point to a more relevant page. If your site is available through HTTP and HTTPS, or with and without www, make sure a redirect has been implemented to clearly indicate the preferred version.
How to resolve the issue?
Use the Inspection Tool to clarify Google-selected canonical. If the page is not a duplicated version of another, make sure the content served across those pages is unique and differs significantly from each other and offers unique value to the end user.
Correct implementation of canonical links will minimise the chances of canonical-related issues appearing in Google Search Console, increase the chances of correct pages being indexed, and prevent unpredictable ranking anomalies, so it’s worth setting them up correctly. If you require support, read our in-depth canonical tag guide. If you want to know more about technical SEO, check out our dedicated services page.


